合成データ生成市場規模、シェア及び業界分析:データタイプ別(テキストデータ、画像・動画データ、表形式データ、その他)、用途別(テストデータ管理、AIトレーニング・開発、企業間データ共有、データ分析・可視化)、業界別(医療、製造、メディア・エンターテインメント、自動車、BFSI、 小売・Eコマース、IT・通信、その他)、および地域別予測、2026-2034年
主要市場インサイト
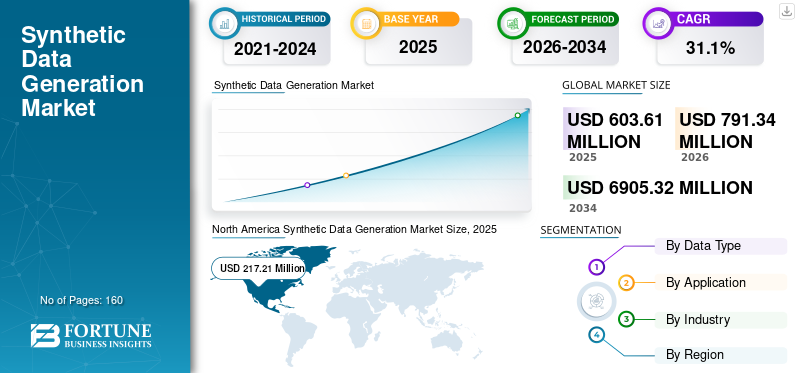
世界の合成データ生成市場規模は、2025年に6億361万米ドルと評価されました。市場は2026年の7億9134万米ドルから2034年までに69億532万米ドルへ成長し、予測期間中に31.10%のCAGRを示すと予測されている。北米は2025年に35.99%の市場シェアで合成データ生成市場を支配した。
合成データ生成は、データがアルゴリズムまたは人為的に作成され、実際の現象に基づいていないプロセスです。合成データは、適切なツールと費用対効果の高いデータ増強技術を使用した統計モデリングおよびシミュレーションプロセスを通じて作成できる元のデータの歪んだバージョンです。
業界の専門家によると、2024年までに、AIおよび分析プロジェクトの開発に使用されるデータのほぼ60%が合成的に生成されます。このデータは、シミュレーション、統計サンプリング、生成敵対的ネットワーク(GAN)などのさまざまな方法を使用して生成でき、数学モデルと機械学習モデルを検証するための生産または運用データの代替テストデータセットとして使用されます。合成データ生成プロセスは、実際のデータを収集するときに役立ちます。
無料サンプルをダウンロード このレポートについて詳しく知るために。
合成データ生成市場に関する要点
- 2025年の市場規模:6億361万米ドル
- 2026年の市場規模:7億9134万米ドル
- 2034年までの市場規模予測:69億532万米ドル
- 年平均成長率(CAGR):2026年~2034年で31.10%
- 北米は2025年に35.99%のシェアを占め、合成データ生成市場を席巻した。
- テキストデータ分野は、予測期間中に最大の市場シェアを占めると予測されている。
- テストデータ管理分野が最大の市場シェアを占めており、ヘルスケア分野は2026年には世界全体で16%を占めると予測されている。
北米
北米は2025年に2億1721万米ドルの評価額で世界市場をリードし、AIとデータ分析の普及が急速に進むことを背景に、2026年には2億8477万米ドルに達すると予測されている。
ヨーロッパ
合成データベンダーへの資金提供の増加と、社内における合成データ処理能力の向上に支えられ、ヨーロッパでは著しい成長が見込まれる。
アジア太平洋地域
アジア太平洋地域は、AI/ML技術およびクラウドベースのインフラへの投資増加により、予測期間中に最も高い成長率を記録すると予測されている。
私たち
AIトレーニング、データプライバシーソリューション、エンタープライズ分析アプリケーションの普及により、市場は力強い成長を遂げている。
日本
市場は、AIイノベーションへの投資拡大、デジタルトランスフォーメーションへの取り組み、そして安全なデータ共有ソリューションへの需要増加から恩恵を受けると予想される。
続きを読む
日本のシンセティックデータ生成市場インサイト
日本では、AI活用の本格化とデータプライバシー規制の強化を背景に、シンセティックデータ生成技術への関心が急速に高まっています。企業は、実データを使わずに高品質な学習データを生成することで、機密情報を保護しつつ、モデル精度の向上や開発スピードの加速を実現しています。また、金融、医療、製造、公共分野など、多様な領域でシミュレーションや検証環境の構築に活用が進んでいます。グローバル市場が拡大する中、日本にとっては、先進的なデータ生成プラットフォームを取り入れ、安全性と革新性を両立したAI基盤を強化する重要な機会となっています。
最新のトレンド
無料サンプルをダウンロード このレポートについて詳しく知るために。
大規模な言語モデル(LLM)の展開を急増させて市場の成長を強化します
大規模な言語モデル(LLM)は、大規模なデータセットと言語モデルを使用するさまざまなソリューションの継続的な開発に基づいて、テキストやその他の種類のコンテンツを翻訳、生成、および予測するのに役立つ学習アルゴリズムです。生成前訓練トランス(GPT)は、GPT-1、GPT-2、およびGPT-3モデルを使用してテキストデータを生成する言語モデルです。 GPT-3は最も複雑なモデルであり、会話データの大きなデータセットを作成するために1億7500万の機械学習パラメーターに達しました。
ウェブサイトやその他のデータベースソリューションの継続的な開発は、小売、ヘルスケア、技術などを含むさまざまな業界の言語モデルの需要を活用しています。これらの言語モデルは、テキスト生成、画像注釈、詐欺検出、会話型AI、およびコード生成のために、異なるエンドユーザーによって使用されます。
したがって、大規模な言語モデル(LLM)の展開の増加は、予測期間中に市場の成長を促進すると予想されています。
合成データ生成市場の成長要因
市場の成長を促進するためのデータプライバシーとセキュリティの需要の増加
一般世界のデータは、一般的なデータ保護規則(GDPR)、カリフォルニア消費者プライバシー法(CCPA)、および健康保険の移植性および説明責任法(HIPAA)によって課される規制とともに、プライバシーの懸念またはコンプライアンスリスクのためにアクセスできません。実際のデータセットを収集するためのプライバシーリスクの上昇は、同様の統計的特性を持つ実際のデータセットの現実的なバージョンである合成データの需要を生成します。この合成データは、実際のデータの代替として使用でき、プライバシー、スケーラビリティ、多様性に関するいくつかの利点を提供します。
たとえば、2023年4月、シンガポールに拠点を置く新興企業であるBetterDataは、個人の機密情報または個人情報を開示することなく、現実世界のデータセットと同様の特性と構造を持つ合成データを使用して、機密データを保護し、強化することなく使用すると宣言しました。機械学習モデル。
抑制要因
データの正確性とリアリズムの欠如は、市場の成長を妨げます
合成データ生成は、ユーザーとテストおよび共有できるデータセットの仮想レプリカを作成します。さらに、このプロセスは、実際の画像と特殊なモデルの詳細をキャプチャするのが困難です。
合成データは現実世界のデータとイノベーションと開発による変化に依存するため、合成データセットを時間の経過とともに一定に保つことは困難です。したがって、組織は合成データの正確性と信頼性を定期的に保証する必要があります。
この要因は、合成データの精度とリアリズムを妨げ、合成データ生成市場の成長を大幅に妨げます。
セグメンテーション
データ型分析による
表形式データは顕著なCAGRを示します人工データに関するプライバシーの懸念に対処することにより
データ型に基づいて、市場はテキストデータ、画像およびビデオデータ、表形式データなどにセグメント化されています。最近、企業はプライバシーの懸念のために実際のデータを収集する際に課題に直面しています。これらの課題は、構造化された表形式に保存できる現実世界データを模倣する人工データの生成につながります。これにより、表形式データの需要が高まります。これは、予測期間中に顕著なCAGRとともに成長すると予想されます。合成表形式データは、生成的敵対的ネットワーク(GAN)を使用して作成して、企業が運用データのプライバシーとセキュリティを強化するのに役立ちます。
調査アナリストによると、合成表形式データを使用して人工知能(AI)モデルを訓練するために、2030年までに実際の構造化データの約3倍速く成長します。
さらに、テキストデータセグメントは、新しい機械学習モデルを使用して自然言語生成システムの使用が増加するため、最大の市場シェアとともに成長すると予測されています。
アプリケーション分析による
セグメントの成長に貢献するテストマネージャーによるテストデータ管理の必要性の向上
アプリケーションに基づいて、市場はテストデータ管理、AIトレーニングと開発、エンタープライズデータ共有、データ分析と視覚化に分かれています。テストデータ管理セグメントは、データテストとデータマスキングのためにテストデータマネージャーによる最小のデータセットの必要性が高まっているため、最大の市場シェアを保持しています。また、GDPRに関連する法的問題を回避することも目的としています。
企業が国境を越えたデータ共有中に困難に直面しているため、エンタープライズデータ共有セグメントは着実に増加します。
業界分析による
このレポートがどのようにビジネスの効率化に役立つかを知るには、 アナリストに相談
BFSI業界は、詐欺事件の数が増加し、アルゴリズム取引の使用が支配的です
業界に基づいて、市場はヘルスケア、製造、メディア&エンターテイメント、自動車、BFSI、小売&eコマース、IT&通信、およびその他。 BFSI業界全体での合成データの使用の増加は、複雑なデータ構造を検証するために、詐欺検出技術、リスク分析、およびアルゴリズム取引を強化するのに役立ちます。したがって、BFSIセグメントは、合成データの使用を強化して、データ駆動型の銀行体験をグローバルな顧客に提供します。
同様に、ヘルスケア業界での合成データの使用の増加が臨床試験、科学研究、医療画像の生成、希少疾患の予測に役立つため、ヘルスケアセグメントは市場の2番目の位置をリードしています。したがって、ヘルスケアセグメントは、予測期間中に最高のCAGRで成長します。
地域の洞察
North America Synthetic Data Generation Market Size, 2025 (USD Million)
この市場の地域分析についての詳細情報を取得するには、 無料サンプルをダウンロード
グローバル市場の範囲は、北米、ヨーロッパ、アジア太平洋、中東とアフリカ、南アメリカの5つの地域に分類されています。
北米は、複数の市場企業の存在により、最大の合成データ生成市場シェアを保持しています。 AIの新興企業、研究機関、ハイテク企業の数の増加は、研究と実験を実施するために高品質の合成データの需要を生み出しています。この要因は、地域全体の市場の成長を促進します。
アジア太平洋地域は、予測期間中に最高のCAGRで成長すると予想されています。これは、AI/MLなどの高度な技術の浸透が増加し、安全なビジネスインフラストラクチャを構築するためのさまざまな業界間のクラウドベースのサービスの採用の増加によるものです。投資の増加生成AIまた、AIテクノロジーに対する企業の焦点の高まりは、予測期間中にアジア太平洋地域の合成データ生成プロセスの需要を推進することが期待されています。
ヨーロッパは、複数の合成データベンダーの存在と構造化された合成データベンダーの資金調達の大幅な成長により、組織の社内合成データ能力の開発をもたらすため、予測期間中に大幅なCAGRで成長すると予想されています。この要因は、予測期間中に市場の成長を推進すると予測されています。
このレポートがどのようにビジネスの効率化に役立つかを知るには、 アナリストに相談
中東とアフリカと南アメリカは増加のために成長していますデジタル変換BFSI、ヘルスケア、自動車、メディア&エンターテイメント全体のイニシアチブ。信頼できる合成データを生成するために、人工知能と機械学習技術と金融および自動車産業を統合すると、両方の地域で合成データ生成の市場成長が促進されます。
主要業界のプレーヤー
主要なプレーヤーは、自分の立場を強化するために合成データの生成に焦点を当てています
合成データ生成会社には、Datagen、主にAI、Tonicai、Inc.、Synthesis AI、Genrocket、Inc.、Gretel Labs、Inc。、K2View Ltd.などが含まれます。さまざまな業界の業種の合成データの生成への投資の増加は、主要なプレーヤーが競争力を維持するのに役立ちます。また、これらの企業は、戦略的パートナーシップ、買収、および協力に取り組んでおり、ビジネスおよび流通ネットワークを拡大し、市場の成長を維持しています。
合成データ生成市場で紹介されている主要企業のリスト:
- ダタゲン(私たち。)
- 主にAI(オーストリア)
- Tonicai、Inc。(米国)
- 合成AI(米国)
- GenRocket、Inc。(米国)
- Gretel Labs、Inc。(私たち。)
- K2View Ltd.(イスラエル)
- Hazy Limited。(英国)
- Replica Analytics Ltd.(カナダ)
- Ydata Labs Inc.(米国)
- Sogeti(フランス)
主要な業界開発:
- 2023年6月:Seed Machine Limitedは、人間中心の合成データプロバイダーであるDevant ABと協力して、注意散漫なドライバーの行動を理解することで輸送の安全性を高めました。このパートナーシップにより、Seed Machineの新しい車両キャビンとDevantの3D人間のアニメーションとコンピューター生成の人間を統合して、キャビン内のセンシングテクノロジーに開発をもたらしました。
- 2023年5月:Synthesis AIは、Snowflake Marketplaceで新しいエンタープライズ合成データセットを開始しました。ここでは、顧客は容易に利用可能な合成AIの合成人間の顔にアクセスして、合成AIの消費者プライバシーを損なうことなくコンピュータービジョンモデルの視覚データを開発できます。
- 2021年12月:Gretel.aiはIllumina、Inc。と提携して、精密医療の開発を強化するために、法医学生物学、バイオテクノロジー、生物系統学など、ゲノミクスやその他の関連分野の研究のための合成データを提供しました。
- 2021年5月:合成データ生成プラットフォームプロバイダーであるParalled Domainは、業界第1のパブリック合成データVisualizerを立ち上げました。これにより、業界のエンジニアが完全に標識された合成カメラとLIDARデータセットと直接対話して、機械学習ソリューションをテスト、展開、トレーニングします。
- 2021年4月:Unity Software Inc.は、建築、エンジニアリング、および建設(AEC)業界の低コストで使用できるコンピュータービジョン人工知能モデルを開発するために、合成画像データセットを開始しました。
報告報告
このレポートは、市場の詳細な分析を提供し、大手企業、製品/サービスタイプ、製品の主要なアプリケーションなどの重要な側面に焦点を当てています。さらに、このレポートは市場動向に関する洞察を提供し、重要な合成データ生成業界の開発を強調しています。上記の要因に加えて、このレポートには、近年市場の成長に貢献しているいくつかの要因が含まれています。
レポートスコープとセグメンテーション
|
属性 |
詳細 |
|
研究期間 |
2021-2034 |
|
基準年 |
2025 |
|
推定年 |
2026 |
|
予測期間 |
2026~2034年 |
|
歴史的時代 |
2021-2024 |
|
成長率 |
2026年から2034年までのCAGRは31.1% |
|
ユニット |
価値(百万米ドル) |
|
セグメンテーション |
データタイプ、アプリケーション、業界、地域別 |
|
データタイプ別 |
|
|
アプリケーション別 |
|
|
業界別 |
|
|
地域別 |
|
よくある質問
市場規模は2034年までに6億90532万米ドルに達すると予測されています。
2025年には市場規模は6億361万米ドルと評価されました。
市場は予測期間中に 31.1% の CAGR で成長すると予測されています。
テストデータセグメントは市場をリードすることが期待されています。
市場の成長を促進するためのデータプライバシーとセキュリティに対する需要の高まり。
Datagen、主にAI、Tonicai、Inc.、Synthesis AI、Genrocket、Inc.、Gretel Labs、Inc.、K2View Ltd.、Sogeti、およびHazy Limitedが市場のトッププレーヤーです。
北米は最高の市場シェアを保持する予定です。
ヘルスケアセグメントは、予測期間中に驚くべきCAGRで成長すると予想されます。
専門家にお問い合わせください 専門家に相談する



- 2021-2034
- 2025
- 2021-2024
- 160
30~60時間の無料カスタマイズ
地域と国のカバレッジを拡大、 セグメント分析、 企業プロフィール、 競合ベンチマーキング、 およびエンドユーザーインサイト。
関連レポート