حجم سوق توليد البيانات الاصطناعية، والمشاركة وتحليل الصناعة، حسب نوع البيانات (بيانات نصية، وبيانات الصور والفيديو، والبيانات الجدولية، وغيرها)، حسب التطبيق (إدارة بيانات الاختبار، والتدريب والتطوير في مجال الذكاء الاصطناعي، ومشاركة بيانات المؤسسة، وتحليلات البيانات وتصورها)، حسب الصناعة (الرعاية الصحية، والتصنيع، والإعلام والترفيه، والسيارات، وBFSI، وتجارة التجزئة والتجارة الإلكترونية، وتكنولوجيا المعلومات والاتصالات، وغيرها)، والتوقعات الإقليمية، 2026-2034
رؤى السوق الرئيسية
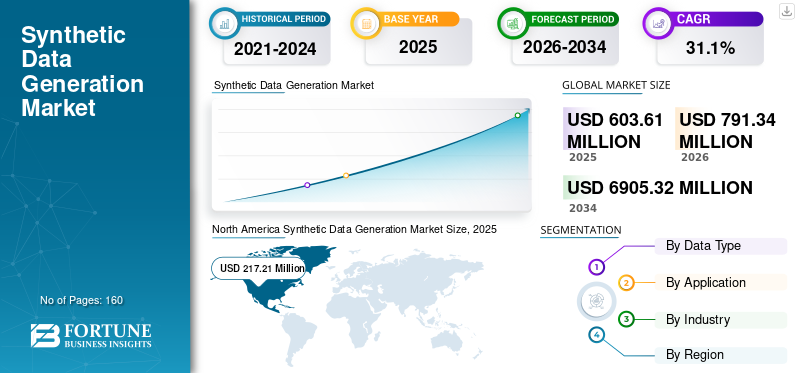
بلغت قيمة سوق توليد البيانات الاصطناعية العالمية 603.61 مليون دولار أمريكي في عام 2025. ومن المتوقع أن ينمو السوق من 791.34 مليون دولار أمريكي في عام 2026 إلى 6905.32 مليون دولار أمريكي بحلول عام 2034، مما يُظهر معدل نمو سنوي مركب قدره 31.10٪ خلال الفترة المتوقعة. سيطرت أمريكا الشمالية على سوق توليد البيانات الاصطناعية بحصة سوقية بلغت 35.99% في عام 2025.
توليد البيانات الاصطناعية هو عملية يتم من خلالها إنشاء البيانات خوارزميًا أو بشكل مصطنع ولا تعتمد على ظواهر العالم الحقيقي. البيانات الاصطناعية هي نسخة مشوهة من البيانات الأصلية التي يمكن إنشاؤها من خلال عمليات النمذجة والمحاكاة الإحصائية باستخدام الأدوات المناسبة وتقنيات زيادة البيانات فعالة من حيث التكلفة.
وفقًا لخبراء الصناعة، بحلول عام 2024، سيتم إنشاء ما يقرب من 60% من البيانات المستخدمة لتطوير مشاريع الذكاء الاصطناعي والتحليلات بشكل صناعي. يمكن إنشاء هذه البيانات باستخدام طرق مختلفة، بما في ذلك عمليات المحاكاة وأخذ العينات الإحصائية وشبكات الخصومة التوليدية (GAN) واستخدامها كمجموعة بيانات اختبار بديلة لبيانات الإنتاج أو البيانات التشغيلية للتحقق من صحة النماذج الرياضية وتدريب نماذج التعلم الآلي. تكون عملية توليد البيانات الاصطناعية مفيدة عندما يكون جمع البيانات الواقعية أمرًا صعبًا أو غير عملي.
تنزيل عينة مجانية للتعرف على المزيد حول هذا التقرير.
الوجبات السريعة في سوق توليد البيانات الاصطناعية
- حجم السوق عام 2025: 603.61 مليون دولار أمريكي
- حجم السوق عام 2026: 791.34 مليون دولار أمريكي
- توقعات حجم السوق لعام 2034: 6,905.32 مليون دولار أمريكي
- معدل النمو السنوي المركب: 31.10% من 2026 إلى 2034
- وهيمنت أمريكا الشمالية على سوق توليد البيانات الاصطناعية بحصة بلغت 35.99% في عام 2025.
- من المتوقع أن يحتفظ قطاع البيانات النصية بأكبر حصة في السوق خلال فترة التنبؤ.
- ويستحوذ قطاع إدارة بيانات الاختبار على الحصة الأكبر من السوق، بينما من المتوقع أن يساهم قطاع الرعاية الصحية بنسبة 16% عالميًا في عام 2026.
أمريكا الشمالية
قادت أمريكا الشمالية السوق العالمية بتقييم قدره 217.21 مليون دولار أمريكي في عام 2025، ومن المتوقع أن تصل إلى 284.77 مليون دولار أمريكي في عام 2026، مدفوعًا بالاعتماد القوي للذكاء الاصطناعي وتحليلات البيانات.
أوروبا
ومن المتوقع أن تشهد أوروبا نمواً كبيراً، مدعوماً بزيادة التمويل لبائعي البيانات الاصطناعية والتقدم في قدرات البيانات الاصطناعية الداخلية.
آسيا والمحيط الهادئ
من المتوقع أن تسجل منطقة آسيا والمحيط الهادئ أعلى معدل نمو خلال الفترة المتوقعة بسبب زيادة الاستثمارات في تقنيات الذكاء الاصطناعي/التعلم الآلي والبنية التحتية القائمة على السحابة.
نحن.
يشهد السوق نموًا قويًا بسبب الاعتماد الواسع النطاق لتدريب الذكاء الاصطناعي وحلول خصوصية البيانات وتطبيقات تحليلات المؤسسات.
اليابان
ومن المتوقع أن يستفيد السوق من الاستثمارات المتزايدة في ابتكارات الذكاء الاصطناعي، ومبادرات التحول الرقمي، وزيادة الطلب على حلول مشاركة البيانات الآمنة.
اقرأ المزيد
أحدث الاتجاهات
زيادة كبيرة في نشر نماذج اللغات الكبيرة (LLM) لزيادة نمو السوق
نماذج اللغة الكبيرة (LLM) هي خوارزميات تعليمية تساعد في ترجمة النصوص وأنواع المحتوى الأخرى وإنشائها والتنبؤ بها استنادًا إلى مجموعات البيانات الكبيرة والتطوير المستمر لمواقع الويب والحلول المتنوعة التي تستخدم نماذج اللغة. المحول التوليدي المدرب مسبقًا (GPT) هو نموذج لغة يقوم بإنشاء بيانات نصية باستخدام نماذج GPT-1 وGPT-2 وGPT-3. يعد GPT-3 هو النموذج الأكثر تعقيدًا وقد وصل إلى 175 مليون معلمة للتعلم الآلي لإنشاء مجموعة بيانات كبيرة من بيانات المحادثة.
يعمل التطوير المستمر لمواقع الويب وحلول قواعد البيانات الأخرى على زيادة الطلب على نماذج اللغة عبر مختلف الصناعات، والتي تشمل البيع بالتجزئة والرعاية الصحية والتكنولوجيا وغيرها. يتم استخدام نماذج اللغة هذه من قبل مستخدمين نهائيين مختلفين لإنشاء النصوص والتعليقات التوضيحية للصور واكتشاف الاحتيال والذكاء الاصطناعي للمحادثة وإنشاء التعليمات البرمجية.
ومن ثم، من المتوقع أن يؤدي الارتفاع في نشر نماذج اللغات الكبيرة (LLM) إلى دفع نمو السوق خلال الفترة المتوقعة.
تنزيل عينة مجانية للتعرف على المزيد حول هذا التقرير.
عوامل نمو سوق توليد البيانات الاصطناعية
تزايد الطلب على خصوصية البيانات وأمنها لتعزيز نمو السوق
لا يمكن الوصول إلى البيانات الواقعية بسبب مخاوف تتعلق بالخصوصية أو مخاطر الامتثال إلى جانب اللوائح التي تفرضها اللائحة العامة لحماية البيانات (GDPR)، وقانون خصوصية المستهلك في كاليفورنيا (CCPA)، وقانون قابلية نقل التأمين الصحي والمساءلة (HIPAA). إن ارتفاع مخاطر الخصوصية المرتبطة بجمع مجموعات البيانات الواقعية يؤدي إلى توليد الطلب على البيانات الاصطناعية، وهي نسخة واقعية من مجموعة البيانات الحقيقية ذات خصائص إحصائية مماثلة. يمكن استخدام هذه البيانات المركبة كبديل للبيانات الحقيقية وتوفر العديد من المزايا فيما يتعلق بالخصوصية وقابلية التوسع والتنوع.
على سبيل المثال، في أبريل 2023، أعلنت شركة Betterdata، وهي شركة ناشئة مقرها سنغافورة، عن استخدام بيانات تركيبية لها خصائص وبنية مماثلة لمجموعة بيانات العالم الحقيقي دون الكشف عن معلومات حساسة أو خاصة للفرد لتأمين البيانات السرية وتعزيزها.التعلم الآلينماذج.
العوامل المقيدة
إن الافتقار إلى دقة البيانات وواقعيتها يعيق نمو السوق
يؤدي إنشاء البيانات الاصطناعية إلى إنشاء نسخ متماثلة افتراضية لمجموعات البيانات التي يمكن اختبارها ومشاركتها مع المستخدمين. علاوة على ذلك، تواجه هذه العملية صعوبة في التقاط التفاصيل الدقيقة لصور العالم الحقيقي والنماذج المتخصصة.
نظرًا لأن البيانات الاصطناعية تعتمد على بيانات العالم الحقيقي والتغيرات الناجمة عن الابتكارات والتطورات، فإن الحفاظ على ثبات مجموعة البيانات الاصطناعية مع مرور الوقت يمثل تحديًا. ومن ثم، يجب على المنظمات التأكد بانتظام من دقة وموثوقية البيانات الاصطناعية.
هذا العامل يعيق دقة البيانات الاصطناعية وواقعيتها، مما يعيق بشكل كبير نمو سوق توليد البيانات الاصطناعية.
تحليل التجزئة
عن طريق تحليل نوع البيانات
تعرض البيانات الجدولية معدل نمو سنوي مركب بارزمن خلال معالجة المخاوف المتعلقة بالخصوصية باستخدام البيانات الاصطناعية
بناءً على نوع البيانات، يتم تقسيم السوق إلى بيانات نصية وبيانات صور وفيديو وبيانات جدولية وغيرها. في الآونة الأخيرة، تواجه الشركات تحديات في جمع البيانات الواقعية بسبب مخاوف الخصوصية. وتؤدي هذه التحديات إلى توليد بيانات مصطنعة تحاكي بيانات العالم الحقيقي، والتي يمكن تخزينها في شكل جدولي منظم. وهذا يعزز الطلب على البيانات الجدولية، والتي من المتوقع أن تنمو بمعدل نمو سنوي مركب بارز خلال فترة التوقعات. يمكن إنشاء بيانات جدولية اصطناعية باستخدام شبكة الخصومة التوليدية (GAN) لمساعدة الشركات على تعزيز خصوصية البيانات التشغيلية وأمانها.
وفقًا لمحللي الأبحاث، فإن استخدام البيانات الجدولية الاصطناعية لتدريب نماذج الذكاء الاصطناعي سوف ينمو بمعدل أسرع بثلاث مرات تقريبًا من البيانات المنظمة الحقيقية بحلول عام 2030.
علاوة على ذلك، من المتوقع أن ينمو قطاع البيانات النصية بأكبر حصة في السوق بسبب زيادة استخدام أنظمة توليد اللغة الطبيعية مع نماذج التعلم الآلي الجديدة.
عن طريق تحليل التطبيق
الحاجة المتزايدة لإدارة بيانات الاختبار من قبل مديري الاختبار مما يساهم في النمو القطاعي
بناءً على التطبيق، ينقسم السوق إلى إدارة بيانات الاختبار، وتدريب وتطوير الذكاء الاصطناعي، ومشاركة بيانات المؤسسة، وتحليل البيانات وتصورها. يمتلك قطاع إدارة بيانات الاختبار أكبر حصة في السوق بسبب الحاجة المتزايدة لأصغر مجموعة من البيانات من قبل مدير بيانات الاختبار لاختبار البيانات وإخفاء البيانات. ويهدف أيضًا إلى تجنب المشكلات القانونية المرتبطة باللائحة العامة لحماية البيانات.
ينمو قطاع مشاركة بيانات المؤسسة بشكل مطرد حيث تواجه المؤسسات صعوبة أثناء مشاركة البيانات عبر الحدود.
من خلال تحليل الصناعة
لمعرفة كيف يمكن لتقريرنا أن يساعد في تبسيط عملك، التحدث إلى المحلل
تهيمن صناعة BFSI بسبب ارتفاع عدد حالات الاحتيال واستخدام التداول الخوارزمي
على أساس الصناعة، ينقسم السوق إلى الرعاية الصحية، والتصنيع، والإعلام والترفيه، والسيارات، وBFSI، وتجارة التجزئة والتجارة الإلكترونية، وتكنولوجيا المعلومات والخدمات.اتصالاتوآخرون. تساعد زيادة استخدام البيانات الاصطناعية عبر صناعة BFSI على تعزيز تقنية الكشف عن الاحتيال، وتحليل المخاطر، والتداول الخوارزمي للتحقق من صحة هياكل البيانات المعقدة. وبالتالي، يؤدي قطاع BFSI إلى تعزيز استخدام البيانات الاصطناعية لتقديم تجارب مصرفية تعتمد على البيانات للعملاء العالميين. ومن المتوقع أن يقود قطاع الرعاية الصحية السوق، حيث سيساهم بنسبة 16% عالميًا في عام 2026.
وبالمثل، يحتل قطاع الرعاية الصحية المركز الثاني في السوق حيث يساعد الاستخدام المتزايد للبيانات الاصطناعية في صناعة الرعاية الصحية على إجراء التجارب السريرية والبحث العلمي وإنشاء الصور الطبية والتنبؤ بالأمراض النادرة. وبالتالي، ينمو قطاع الرعاية الصحية بأعلى معدل نمو سنوي مركب خلال الفترة المتوقعة.
التحليل الإقليمي
North America Synthetic Data Generation Market Size, 2025 (USD Million)
للحصول على مزيد من المعلومات حول التحليل الإقليمي لهذا السوق، تنزيل عينة مجانية
يتم تصنيف نطاق السوق العالمية عبر خمس مناطق، أمريكا الشمالية وأوروبا وآسيا والمحيط الهادئ والشرق الأوسط وأفريقيا وأمريكا الجنوبية.
أمريكا الشمالية
سيطرت أمريكا الشمالية على السوق بقيمة 217.21 مليار دولار أمريكي في عام 2025 و284.77 مليار دولار أمريكي في عام 2026. وتمتلك أمريكا الشمالية أكبر حصة في سوق توليد البيانات الاصطناعية، وذلك بسبب وجود لاعبين متعددين في السوق. ويعمل العدد المتزايد من الشركات الناشئة في مجال الذكاء الاصطناعي، ومعاهد البحوث، وشركات التكنولوجيا الفائقة على توليد الطلب على البيانات الاصطناعية عالية الجودة لإجراء البحوث والتجارب. هذا العامل يغذي نمو السوق في جميع أنحاء المنطقة.
آسيا والمحيط الهادئ
من المتوقع أن تنمو منطقة آسيا والمحيط الهادئ بأعلى معدل نمو سنوي مركب خلال الفترة المتوقعة. ويرجع ذلك إلى الاختراق المتزايد للتقنيات المتقدمة مثل الذكاء الاصطناعي والتعلم الآلي والاعتماد المتزايد للخدمات السحابية بين مختلف الصناعات لبناء بنية تحتية آمنة للأعمال. زيادة الاستثمار فيالذكاء الاصطناعي التوليديومن المتوقع أن يؤدي التركيز المتزايد للشركات على تكنولوجيا الذكاء الاصطناعي إلى زيادة الطلب على عمليات توليد البيانات الاصطناعية في منطقة آسيا والمحيط الهادئ خلال الفترة المتوقعة.
أوروبا
من المتوقع أن تنمو أوروبا بمعدل نمو سنوي مركب كبير خلال الفترة المتوقعة بسبب وجود العديد من بائعي البيانات الاصطناعية والنمو الهائل في تمويل بائعي البيانات الاصطناعية المنظمة لتحقيق التطورات في قدرات البيانات الاصطناعية الداخلية للمؤسسات. ومن المتوقع أن يدفع هذا العامل نمو السوق خلال الفترة المتوقعة.
لمعرفة كيف يمكن لتقريرنا أن يساعد في تبسيط عملك، التحدث إلى المحلل
الشرق الأوسط وأفريقيا وأمريكا الجنوبية
منطقة الشرق الأوسط وأفريقيا وأمريكا الجنوبية تنمو بسبب الزيادةالتحول الرقميالمبادرات عبر BFSI والرعاية الصحية والسيارات والإعلام والترفيه. إن دمج تقنيات الذكاء الاصطناعي والتعلم الآلي مع التمويل وصناعة السيارات لتوليد بيانات اصطناعية موثوقة يغذي نمو سوق توليد البيانات الاصطناعية في كلا المنطقتين.
اللاعبون الرئيسيون في الصناعة
يركز اللاعبون الرئيسيون على توليد البيانات الاصطناعية لتعزيز مواقعهم
تشمل شركات توليد البيانات الاصطناعية Datagen وMOSTLY AI وTonicAI, Inc. وSynthesis AI وGenRocket, Inc. وGretel Labs, Inc. وK2view Ltd.، وغيرها. تساعد زيادة الاستثمارات في توليد البيانات الاصطناعية لمختلف قطاعات الصناعة اللاعبين الرئيسيين في الحفاظ على قدرتهم التنافسية. وتشارك هذه الشركات أيضًا في شراكات استراتيجية وعمليات استحواذ وتعاون لتوسيع أعمالها وشبكة التوزيع والحفاظ على نمو السوق.
قائمة الشركات الرئيسية في سوق توليد البيانات الاصطناعية:
- داتاجين(نحن.)
- في الغالب منظمة العفو الدولية (النمسا)
- شركة TonicAI, Inc. (الولايات المتحدة)
- الذكاء الاصطناعي الاصطناعي (الولايات المتحدة)
- شركة جينروكيت (الولايات المتحدة)
- شركة جريتيل لابز(نحن.)
- K2view المحدودة.(إسرائيل)
- ضبابي المحدودة.(المملكة المتحدة.)
- Replica Analytics Ltd. (كندا)
- شركة YData Labs Inc. (الولايات المتحدة)
- سوجيتي (فرنسا)
التطورات الصناعية الرئيسية:
- يونيو 2023:تعاونت شركة Seeing Machine Limited مع Devant AB، وهي شركة مزودة للبيانات الاصطناعية التي تركز على الإنسان، لتعزيز سلامة النقل من خلال فهم سلوك السائق المشتت. أدت هذه الشراكة إلى دمج مقصورة مركبة Seeing Machine الجديدة مع الرسوم المتحركة البشرية ثلاثية الأبعاد من Devant والبشر المولدين بالكمبيوتر لتحقيق التطوير في تكنولوجيا الاستشعار داخل المقصورة.
- مايو 2023:أطلقت Synthesis AI مجموعة بيانات اصطناعية جديدة للمؤسسة في سوق Snowflake، حيث يمكن لعملائها الوصول إلى الوجوه البشرية الاصطناعية المتوفرة بسهولة من Synthesis AI لتطوير البيانات المرئية لنموذج رؤية الكمبيوتر دون المساس بخصوصية المستهلك في Synthesis AI.
- ديسمبر 2021:عقدت Gretel.ai شراكة مع شركة Illumina, Inc. لتقديم بيانات تركيبية للأبحاث في علم الجينوم والمجالات الأخرى ذات الصلة، بما في ذلك علم الأحياء الشرعي والتكنولوجيا الحيوية والنظاميات البيولوجية لتعزيز تطوير الطب الدقيق.
- مايو 2021:أطلقت شركة Parallel Domain، وهي مزود منصة لتوليد البيانات الاصطناعية، أول مصور للبيانات الاصطناعية العامة في الصناعة، والذي يساعد مهندسي الصناعة على التفاعل مباشرة مع الكاميرا الاصطناعية ذات العلامات الكاملة ومجموعات بيانات LiDAR لاختبار حلول التعلم الآلي ونشرها وتدريبها.
- أبريل 2021:أطلقت شركة Unity Software Inc. مجموعات بيانات الصور الاصطناعية لتطوير نماذج الذكاء الاصطناعي لرؤية الكمبيوتر والتي يمكن استخدامها بتكاليف أقل في صناعات الهندسة المعمارية والهندسة والبناء (AEC).
تغطية التقرير
يقدم التقرير تحليلاً مفصلاً للسوق ويركز على الجوانب الرئيسية مثل الشركات الرائدة وأنواع المنتجات/الخدمات والتطبيقات الرائدة للمنتج. علاوة على ذلك، يقدم التقرير نظرة ثاقبة لاتجاهات السوق ويسلط الضوء على التطورات الرئيسية في صناعة توليد البيانات الاصطناعية. بالإضافة إلى العوامل المذكورة أعلاه، يشمل التقرير عدة عوامل ساهمت في نمو السوق في السنوات الأخيرة.
طلب التخصيص للحصول على رؤى سوقية شاملة.
نطاق التقرير والتجزئة
|
يصف |
تفاصيل |
|
فترة الدراسة |
2021-2034 |
|
سنة الأساس |
2025 |
|
السنة المقدرة |
2026 |
|
فترة التنبؤ |
2026-2034 |
|
الفترة التاريخية |
2021-2024 |
|
معدل النمو |
معدل نمو سنوي مركب قدره 31.1% من عام 2026 إلى عام 2034 |
|
وحدة |
القيمة (مليون دولار أمريكي) |
|
التقسيم |
حسب نوع البيانات والتطبيق والصناعة والمنطقة |
|
حسب نوع البيانات |
|
|
عن طريق التطبيق |
|
|
حسب الصناعة |
|
|
حسب المنطقة |
|
الأسئلة الشائعة
ومن المتوقع أن يصل السوق إلى 6905.32 مليون دولار أمريكي بحلول عام 2034.
وفي عام 2025، بلغت قيمة السوق 603.61 مليون دولار أمريكي.
من المتوقع أن ينمو السوق بمعدل نمو سنوي مركب قدره 31.1٪ خلال الفترة المتوقعة.
ومن المتوقع أن يقود قطاع بيانات الاختبار السوق.
تزايد الطلب على خصوصية البيانات وأمنها لدعم نمو السوق.
تعد Datagen وMOSTLY AI وTonicAI, Inc. وSynthesis AI وGenRocket, Inc. وGretel Labs, Inc. وK2view Ltd. وSogeti وHazy Limited من أفضل اللاعبين في السوق.
ومن المتوقع أن تستحوذ أمريكا الشمالية على أعلى حصة في السوق.
من المتوقع أن ينمو قطاع الرعاية الصحية بمعدل نمو سنوي مركب ملحوظ خلال الفترة المتوقعة.



- 2021-2034
- 2025
- 2021-2024
- 160
احصل على 30 إلى 60 ساعة من التخصيص المجاني
توسيع التغطية الإقليمية والدولية، تحليل القطاعات، ملفات الشركات، المعيارية التنافسية، ورؤى المستخدم النهائي.
التقارير ذات الصلة