Tamaño del mercado de generación de datos sintéticos, participación y análisis de la industria, por tipo de datos (datos de texto, datos de imágenes y videos, datos tabulares y otros), por aplicación (gestión de datos de prueba, capacitación y desarrollo de inteligencia artificial, intercambio de datos empresariales y análisis y visualización de datos), por industria (atención médica, manufactura, medios y entretenimiento, automoción, BFSI, comercio minorista y electrónico, TI y telecomunicaciones, y otros) y pronóstico regional, 2026-2034
INFORMACIÓN CLAVE DEL MERCADO
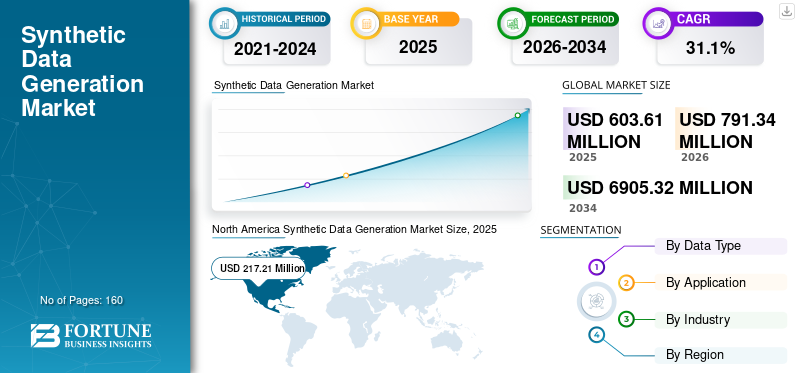
El tamaño del mercado mundial de generación de datos sintéticos se valoró en 603,61 millones de dólares en 2025. Se prevé que el mercado crezca de 791,34 millones de dólares en 2026 a 6905,32 millones de dólares en 2034, exhibiendo una tasa compuesta anual del 31,10% durante el período previsto. América del Norte dominó el mercado de generación de datos sintéticos con una cuota de mercado del 35,99% en 2025.
La generación de datos sintéticos es un proceso mediante el cual los datos se crean algorítmica o artificialmente y no se basan en fenómenos del mundo real. Los datos sintéticos son una versión distorsionada de los datos originales que se pueden crear mediante procesos de simulación y modelado estadístico utilizando herramientas adecuadas y técnicas rentables de aumento de datos.
Según los expertos de la industria, para 2024, casi el 60% de los datos utilizados para desarrollar proyectos de análisis e inteligencia artificial se generarán sintéticamente. Estos datos se pueden generar utilizando varios métodos, incluidas simulaciones, muestreo estadístico y redes generativas adversas (GAN), y se utilizan como un conjunto de datos de prueba sustituto para datos operativos o de producción para validar modelos matemáticos y entrenar modelos de aprendizaje automático. El proceso de generación de datos sintéticos es útil cuando la recopilación de datos del mundo real resulta desafiante o poco práctica.
Descargar muestra gratuita para conocer más sobre este informe.
Conclusiones del mercado de generación de datos sintéticos
- Tamaño del mercado en 2025: 603,61 millones de dólares
- Tamaño del mercado en 2026: 791,34 millones de dólares
- Tamaño del mercado previsto para 2034: 6.905,32 millones de dólares
- CAGR: 31,10% de 2026 a 2034
- América del Norte dominó el mercado de generación de datos sintéticos con una participación del 35,99% en 2025.
- Se proyecta que el segmento de datos de texto tendrá la mayor participación de mercado durante el período de pronóstico.
- El segmento de gestión de datos de pruebas representó la mayor cuota de mercado, mientras que se espera que el segmento de atención sanitaria contribuya con el 16% a nivel mundial en 2026.
América del norte
América del Norte lideró el mercado global con una valoración de 217,21 millones de dólares en 2025 y se espera que alcance los 284,77 millones de dólares en 2026, impulsada por una fuerte adopción de la inteligencia artificial y el análisis de datos.
Europa
Se espera que Europa sea testigo de un crecimiento significativo, respaldado por una mayor financiación para los proveedores de datos sintéticos y avances en las capacidades internas de datos sintéticos.
Asia Pacífico
Se proyecta que Asia Pacífico registre la tasa de crecimiento más alta durante el período previsto debido al aumento de las inversiones en tecnologías AI/ML e infraestructura basada en la nube.
A NOSOTROS.
El mercado está experimentando un fuerte crecimiento debido a la adopción generalizada de capacitación en inteligencia artificial, soluciones de privacidad de datos y aplicaciones de análisis empresarial.
Japón
Se espera que el mercado se beneficie de las crecientes inversiones en innovación en inteligencia artificial, iniciativas de transformación digital y la creciente demanda de soluciones seguras para compartir datos.
Leer más
ÚLTIMAS TENDENCIAS
Aumento en la implementación de modelos de lenguajes grandes (LLM) para aumentar el crecimiento del mercado
Los modelos de lenguaje grandes (LLM) son algoritmos de aprendizaje que ayudan a traducir, generar y predecir texto y otros tipos de contenido basados en grandes conjuntos de datos y el desarrollo continuo de sitios web y diversas soluciones que utilizan modelos de lenguaje. Transformador generativo preentrenado (GPT) es un modelo de lenguaje que genera datos de texto utilizando los modelos GPT-1, GPT-2 y GPT-3. GPT-3 es el modelo más complejo y ha alcanzado 175 millones de parámetros de aprendizaje automático para crear un gran conjunto de datos conversacionales.
El desarrollo continuo de sitios web y otras soluciones de bases de datos aprovecha la demanda de modelos lingüísticos en diversas industrias, que incluyen el comercio minorista, la atención médica, la tecnología y otras. Estos modelos de lenguaje son utilizados por diferentes usuarios finales para generación de texto, anotación de imágenes, detección de fraude, IA conversacional y generación de código.
Por lo tanto, se prevé que el aumento en la implementación de modelos de lenguajes grandes (LLM) impulse el crecimiento del mercado durante el período de pronóstico.
Descargar muestra gratuita para conocer más sobre este informe.
FACTORES DE CRECIMIENTO DEL MERCADO DE GENERACIÓN DE DATOS SINTÉTICOS
La creciente demanda de privacidad y seguridad de los datos impulsará el crecimiento del mercado
No se puede acceder a los datos del mundo real debido a preocupaciones de privacidad o riesgos de cumplimiento junto con las regulaciones impuestas por el Reglamento General de Protección de Datos (GDPR), la Ley de Privacidad del Consumidor de California (CCPA) y la Ley de Responsabilidad y Portabilidad de Seguros Médicos (HIPAA). El aumento de los riesgos para la privacidad al recopilar conjuntos de datos del mundo real genera una demanda de datos sintéticos, una versión realista del conjunto de datos real con propiedades estadísticas similares. Estos datos sintetizados se pueden utilizar como alternativa a los datos reales y ofrecen varias ventajas en materia de privacidad, escalabilidad y diversidad.
Por ejemplo, en abril de 2023, Betterdata, una startup con sede en Singapur, declaró que utiliza datos sintéticos que tienen características y estructura similares a los conjuntos de datos del mundo real sin revelar información confidencial o privada de un individuo para proteger los datos confidenciales y mejorarlos.aprendizaje automáticomodelos.
FACTORES RESTRICTIVOS
La falta de precisión y realismo de los datos obstaculiza el crecimiento del mercado
La generación de datos sintéticos crea réplicas virtuales de conjuntos de datos que pueden probarse y compartirse con los usuarios. Además, este proceso enfrenta dificultades para capturar los detalles minuciosos de imágenes del mundo real y modelos especializados.
Como los datos sintéticos dependen de datos del mundo real y de cambios debidos a innovaciones y desarrollos, mantener el conjunto de datos sintéticos constante a lo largo del tiempo es un desafío. Por lo tanto, las organizaciones deben garantizar periódicamente la precisión y confiabilidad de los datos sintéticos.
Este factor obstaculiza la precisión y el realismo de los datos sintéticos, lo que obstaculiza significativamente el crecimiento del mercado de generación de datos sintéticos.
ANÁLISIS DE SEGMENTACIÓN
Por análisis de tipo de datos
Los datos tabulares muestran una CAGR destacadaabordando preocupaciones de privacidad con datos artificiales
Según el tipo de datos, el mercado se segmenta en datos de texto, datos de imágenes y videos, datos tabulares y otros. Recientemente, las empresas enfrentan desafíos a la hora de recopilar datos de la vida real debido a preocupaciones de privacidad. Estos desafíos conducen a la generación de datos artificiales que imitan los datos del mundo real, que pueden almacenarse en formato tabular estructurado. Esto impulsa la demanda de datos tabulares, que se espera que crezca con una CAGR destacada durante el período de pronóstico. Se pueden crear datos tabulares sintéticos utilizando Generative Adversarial Network (GAN) para ayudar a las empresas a mejorar la privacidad y seguridad de los datos operativos.
Según los analistas de investigación, el uso de datos tabulares sintéticos para entrenar modelos de Inteligencia Artificial (IA) crecerá aproximadamente tres veces más rápido que los datos estructurados reales para 2030.
Además, se proyecta que el segmento de datos de texto crecerá con la mayor participación de mercado debido al creciente uso de sistemas de generación de lenguaje natural con nuevos modelos de aprendizaje automático.
Por análisis de aplicaciones
La creciente necesidad de gestión de datos de prueba por parte de los administradores de pruebas contribuye al crecimiento segmentario
Según la aplicación, el mercado se divide en gestión de datos de prueba, capacitación y desarrollo de IA, intercambio de datos empresariales y análisis y visualización de datos. El segmento de gestión de datos de prueba tiene la mayor participación de mercado debido a la creciente necesidad del administrador de datos de prueba del conjunto más pequeño de datos para las pruebas y el enmascaramiento de datos. También pretende evitar problemas legales asociados al RGPD.
El segmento de intercambio de datos empresariales crece de manera constante a medida que las empresas enfrentan dificultades durante el intercambio de datos transfronterizos.
Por análisis de la industria
Para saber cómo nuestro informe puede ayudar a optimizar su negocio, Hable con un analista
La industria BFSI domina debido al aumento en el número de casos de fraude y el uso de operaciones algorítmicas
Según la industria, el mercado se divide en atención médica, fabricación, medios y entretenimiento, automoción, BFSI, comercio minorista y electrónico, TI ytelecomunicacióny otros. El aumento del uso de datos sintéticos en la industria BFSI ayuda a mejorar la técnica de detección de fraude, el análisis de riesgos y el comercio algorítmico para validar estructuras de datos complejas. Por lo tanto, el segmento BFSI lidera la mejora del uso de datos sintéticos para ofrecer experiencias bancarias basadas en datos a clientes globales. Se espera que el segmento de atención médica lidere el mercado, contribuyendo con el 16% a nivel mundial en 2026.
De manera similar, el segmento de atención médica ocupa la segunda posición en el mercado, ya que el uso cada vez mayor de datos sintéticos en la industria de la salud ayuda a realizar ensayos clínicos, investigaciones científicas, generar imágenes médicas y predecir enfermedades raras. Por lo tanto, el segmento de atención médica crece con la CAGR más alta durante el período de pronóstico.
ANÁLISIS REGIONAL
North America Synthetic Data Generation Market Size, 2025 (USD Million)
Para obtener más información sobre el análisis regional de este mercado, Descargar muestra gratuita
El alcance del mercado global se clasifica en cinco regiones: América del Norte, Europa, Asia Pacífico, Medio Oriente y África y América del Sur.
América del norte
América del Norte dominó el mercado con una valoración de 217,21 mil millones de dólares en 2025 y 284,77 mil millones de dólares en 2026. América del Norte tiene la mayor participación de mercado de generación de datos sintéticos, debido a la presencia de múltiples actores del mercado. El creciente número de nuevas empresas de IA, institutos de investigación y empresas de alta tecnología genera una demanda de datos sintéticos de alta calidad para realizar investigaciones y experimentos. Este factor impulsa el crecimiento del mercado en toda la región.
Asia Pacífico
Se espera que Asia Pacífico crezca con la CAGR más alta durante el período previsto. Se debe a la creciente penetración de tecnologías avanzadas como AI/ML y a la creciente adopción de servicios basados en la nube entre diferentes industrias para construir una infraestructura empresarial segura. Incremento de la inversión enIA generativay se prevé que el creciente enfoque de las empresas en la tecnología de inteligencia artificial impulsará la demanda de procesos de generación de datos sintéticos en Asia Pacífico durante el período de pronóstico.
Europa
Se espera que Europa crezca con una CAGR significativa durante el período de pronóstico debido a la presencia de múltiples proveedores de datos sintéticos y al tremendo crecimiento en la financiación para que los proveedores de datos sintéticos estructurados aporten avances en las capacidades internas de datos sintéticos de las organizaciones. Se proyecta que este factor impulsará el crecimiento del mercado durante el período de pronóstico.
Para saber cómo nuestro informe puede ayudar a optimizar su negocio, Hable con un analista
Medio Oriente, África y Sudamérica
Medio Oriente, África y América del Sur están creciendo debido al aumentotransformación digitaliniciativas en BFSI, atención médica, automoción y medios y entretenimiento. La integración de tecnologías de inteligencia artificial y aprendizaje automático con las finanzas y la industria automotriz para generar datos sintéticos confiables impulsa el crecimiento del mercado de generación de datos sintéticos en ambas regiones.
JUGADORES CLAVE DE LA INDUSTRIA
Los actores clave se centran en generar datos sintéticos para fortalecer su posición
Las empresas de generación de datos sintéticos incluyen Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc. y K2view Ltd., entre otras. Las crecientes inversiones en la generación de datos sintéticos para diferentes sectores industriales están ayudando a los actores clave a mantener su ventaja competitiva. Estas empresas también participan en asociaciones, adquisiciones y colaboraciones estratégicas para expandir su red comercial y de distribución y mantener el crecimiento del mercado.
Lista de empresas clave perfiladas en el mercado de generación de datos sintéticos:
- Generador de datos(A NOSOTROS.)
- MAYORMENTE IA (Austria)
- TonicAI, Inc. (EE. UU.)
- Síntesis de IA (EE. UU.)
- GenRocket, Inc. (EE. UU.)
- Laboratorios Gretel, Inc.(A NOSOTROS.)
- K2view Ltd.(Israel)
- Nebuloso limitado.(Reino Unido)
- Replica Analytics Ltd. (Canadá)
- YData Labs Inc. (EE. UU.)
- Sogeti (Francia)
DESARROLLOS CLAVE DE LA INDUSTRIA:
- Junio de 2023:Seeing Machine Limited colaboró con Devant AB, un proveedor de datos sintéticos centrado en el ser humano, para mejorar la seguridad del transporte al comprender el comportamiento de los conductores distraídos. Esta asociación llevó a integrar la nueva cabina del vehículo de Seeing Machine con la animación humana 3D de Devant y humanos generados por computadora para generar desarrollo en la tecnología de detección en la cabina.
- Mayo de 2023:Synthesis AI lanzó un nuevo conjunto de datos sintéticos empresariales en el mercado Snowflake, donde sus clientes pueden acceder a los rostros humanos sintéticos de Synthesis AI disponibles para desarrollar datos visuales para el modelo de visión por computadora sin comprometer la privacidad del consumidor de Synthesis AI.
- Diciembre de 2021:Gretel.ai se asoció con Illumina, Inc. para entregar datos sintéticos para la investigación en genómica y otros campos relacionados, incluida la biología forense, la biotecnología y la sistemática biológica para mejorar el desarrollo de la medicina de precisión.
- Mayo de 2021:Parallel Domain, un proveedor de plataforma de generación de datos sintéticos, lanzó el primer visualizador público de datos sintéticos de la industria, que ayuda a los ingenieros de la industria a interactuar directamente con la cámara sintética completamente etiquetada y los conjuntos de datos LiDAR para probar, implementar y entrenar soluciones de aprendizaje automático.
- Abril de 2021:Unity Software Inc. lanzó conjuntos de datos de imágenes sintéticas para desarrollar modelos de inteligencia artificial de visión por computadora que puedan usarse a costos más bajos en las industrias de arquitectura, ingeniería y construcción (AEC).
COBERTURA DEL INFORME
El informe proporciona un análisis detallado del mercado y se centra en aspectos clave como empresas líderes, tipos de productos/servicios y aplicaciones líderes del producto. Además, el informe ofrece información sobre las tendencias del mercado y destaca desarrollos clave de la industria de generación de datos sintéticos. Además de los factores anteriores, el informe abarca varios factores que han contribuido al crecimiento del mercado en los últimos años.
Solicitud de personalización para obtener un conocimiento amplio del mercado.
Alcance y segmentación del informe
|
ATRIBUTO |
DETALLES |
|
Período de estudio |
2021-2034 |
|
Año base |
2025 |
|
Año estimado |
2026 |
|
Período de pronóstico |
2026-2034 |
|
Período histórico |
2021-2024 |
|
Índice de crecimiento |
CAGR del 31,1% de 2026 a 2034 |
|
Unidad |
Valor (millones de dólares) |
|
Segmentación |
Por tipo de datos, aplicación, industria y región |
|
Por tipo de datos |
|
|
Por aplicación |
|
|
Por industria |
|
|
Por región |
|
Preguntas frecuentes
Se prevé que el mercado alcance los 6.905,32 millones de dólares en 2034.
En 2025, el mercado estaba valorado en 603,61 millones de dólares.
Se prevé que el mercado crezca a una tasa compuesta anual del 31,1% durante el período previsto.
Se espera que el segmento de datos de prueba lidere el mercado.
La creciente demanda de privacidad y seguridad de los datos para impulsar el crecimiento del mercado.
Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc., K2view Ltd., Sogeti y Hazy Limited son los principales actores del mercado.
Se espera que América del Norte tenga la mayor cuota de mercado.
Se espera que el segmento de atención médica crezca con una CAGR notable durante el período de pronóstico.
Póngase en contacto con nuestras expertas Habla con un experto



- 2021-2034
- 2025
- 2021-2024
- 160
Obtenga un 20% de personalización gratuita
Ampliar la cobertura regional y por país, Análisis de segmentos, Perfiles de empresas, Benchmarking competitivo, e información sobre el usuario final.
Informes relacionados