Taille du marché de la génération de données synthétiques, part et analyse de l’industrie, par type de données (données textuelles, données d’image et vidéo, données tabulaires et autres), par application (gestion des données de test, formation et développement de l’IA, partage de données d’entreprise et analyse et visualisation de données), par industrie (santé, fabrication, médias et divertissement, automobile, BFSI, vente au détail et commerce électronique, informatique et télécommunications, et autres) et prévisions régionales, 2026-2034
APERÇUS CLÉS DU MARCHÉ
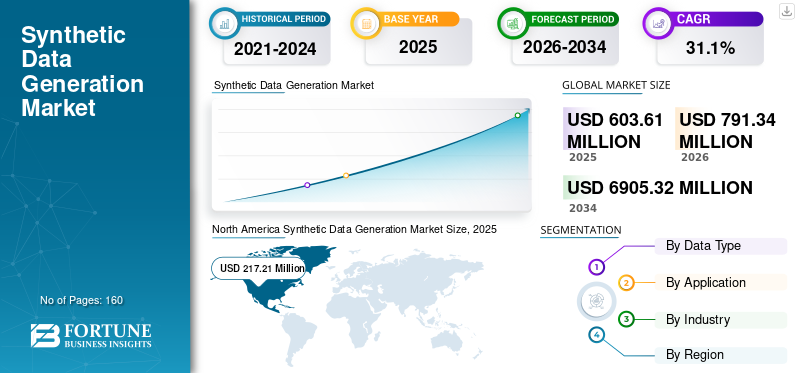
La taille du marché mondial de la génération de données synthétiques était évaluée à 603,61 millions de dollars en 2025. Le marché devrait passer de 791,34 millions de dollars en 2026 à 6 905,32 millions de dollars d’ici 2034, avec un TCAC de 31,10 % au cours de la période de prévision. L’Amérique du Nord a dominé le marché de la génération de données synthétiques avec une part de marché de 35,99 % en 2025.
La génération de données synthétiques est un processus par lequel les données sont créées de manière algorithmique ou artificielle et n'est pas basée sur des phénomènes du monde réel. Les données synthétiques sont une version déformée des données originales qui peuvent être créées grâce à des processus de modélisation et de simulation statistiques utilisant des outils appropriés et des techniques d'augmentation des données rentables.
Selon les experts du secteur, d’ici 2024, près de 60 % des données utilisées pour développer des projets d’IA et d’analyse seront générées de manière synthétique. Ces données peuvent être générées à l'aide de diverses méthodes, notamment des simulations, l'échantillonnage statistique et des réseaux contradictoires génératifs (GAN), et sont utilisées comme ensemble de données de test de remplacement pour les données de production ou opérationnelles afin de valider des modèles mathématiques et de former des modèles d'apprentissage automatique. Le processus de génération de données synthétiques est utile lorsque la collecte de données du monde réel est difficile ou peu pratique.
Télécharger un échantillon gratuit pour en savoir plus sur ce rapport.
Points à retenir sur le marché de la génération de données synthétiques
- Taille du marché en 2025 : 603,61 millions USD
- Taille du marché en 2026 : 791,34 millions USD
- Taille du marché prévue pour 2034 : 6 905,32 millions de dollars
- TCAC : 31,10 % de 2026 à 2034
- L'Amérique du Nord a dominé le marché de la génération de données synthétiques avec une part de 35,99 % en 2025.
- Le segment des données textuelles devrait détenir la plus grande part de marché au cours de la période de prévision.
- Le segment de la gestion des données de test représentait la plus grande part de marché, tandis que le segment des soins de santé devrait contribuer à hauteur de 16 % à l’échelle mondiale en 2026.
Amérique du Nord
L’Amérique du Nord était en tête du marché mondial avec une valorisation de 217,21 millions de dollars en 2025 et devrait atteindre 284,77 millions de dollars en 2026, grâce à une forte adoption de l’IA et de l’analyse des données.
Europe
L’Europe devrait connaître une croissance significative, soutenue par l’augmentation du financement des fournisseurs de données synthétiques et par les progrès des capacités internes de données synthétiques.
Asie-Pacifique
L’Asie-Pacifique devrait enregistrer le taux de croissance le plus élevé au cours de la période de prévision en raison de l’augmentation des investissements dans les technologies IA/ML et dans les infrastructures basées sur le cloud.
NOUS.
Le marché connaît une forte croissance en raison de l’adoption généralisée de formations en IA, de solutions de confidentialité des données et d’applications d’analyse d’entreprise.
Japon
Le marché devrait bénéficier d’investissements croissants dans l’innovation en matière d’IA, d’initiatives de transformation numérique et d’une demande croissante de solutions sécurisées de partage de données.
En savoir plus
DERNIÈRES TENDANCES
Augmentation du déploiement de grands modèles linguistiques (LLM) pour augmenter la croissance du marché
Les grands modèles linguistiques (LLM) sont des algorithmes d'apprentissage qui aident à traduire, générer et prédire du texte et d'autres types de contenu sur la base de grands ensembles de données et du développement continu de sites Web et de diverses solutions utilisant des modèles linguistiques. Generative Pre-trained Transformer (GPT) est un modèle de langage qui génère des données textuelles à l'aide des modèles GPT-1, GPT-2 et GPT-3. GPT-3 est le modèle le plus complexe et a atteint 175 millions de paramètres d'apprentissage automatique pour créer un vaste ensemble de données conversationnelles.
Le développement continu de sites Web et d'autres solutions de bases de données exploite la demande de modèles de langage dans divers secteurs, notamment la vente au détail, la santé, la technologie et autres. Ces modèles de langage sont utilisés par différents utilisateurs finaux pour la génération de texte, l'annotation d'images, la détection de fraude, l'IA conversationnelle et la génération de code.
Par conséquent, l’augmentation du déploiement de grands modèles linguistiques (LLM) devrait stimuler la croissance du marché au cours de la période de prévision.
Télécharger un échantillon gratuit pour en savoir plus sur ce rapport.
FACTEURS DE CROISSANCE DU MARCHÉ DE LA GÉNÉRATION DE DONNÉES SYNTHÉTIQUES
Demande croissante de confidentialité et de sécurité des données pour alimenter la croissance du marché
Les données du monde réel ne sont pas accessibles en raison de problèmes de confidentialité ou de risques de conformité ainsi que des réglementations imposées par le Règlement général sur la protection des données (RGPD), le California Consumer Privacy Act (CCPA) et le Health Insurance Portability and Accountability Act (HIPAA). L’augmentation des risques liés à la confidentialité liés à la collecte d’ensembles de données du monde réel génère une demande de données synthétiques, une version réaliste de l’ensemble de données réelles présentant des propriétés statistiques similaires. Ces données synthétisées peuvent être utilisées comme alternative aux données réelles et offrent plusieurs avantages en termes de confidentialité, d'évolutivité et de diversité.
Par exemple, en avril 2023, Betterdata, une startup basée à Singapour, a déclaré utiliser des données synthétiques présentant des caractéristiques et une structure similaires à celles du monde réel, sans divulguer les informations sensibles ou privées d'un individu, afin de sécuriser les données confidentielles et d'améliorer leurs performances.apprentissage automatiquemodèles.
FACTEURS DE RETENUE
Le manque de précision et de réalisme des données entrave la croissance du marché
La génération de données synthétiques crée des répliques virtuelles d'ensembles de données qui peuvent être testées et partagées avec les utilisateurs. De plus, ce processus se heurte à des difficultés pour capturer les moindres détails des images du monde réel et des modèles spécialisés.
Étant donné que les données synthétiques dépendent de données du monde réel et des changements dus aux innovations et aux développements, il est difficile de maintenir l’ensemble de données synthétiques constant dans le temps. Par conséquent, les organisations doivent régulièrement s’assurer de l’exactitude et de la fiabilité des données synthétiques.
Ce facteur entrave l’exactitude et le réalisme des données synthétiques, entravant considérablement la croissance du marché de la génération de données synthétiques.
ANALYSE DE SEGMENTATION
Par analyse de type de données
Les données tabulaires présentent un TCAC importanten répondant aux problèmes de confidentialité avec des données artificielles
En fonction du type de données, le marché est segmenté en données textuelles, données d’images et vidéo, données tabulaires et autres. Récemment, les entreprises sont confrontées à des difficultés dans la collecte de données réelles en raison de problèmes de confidentialité. Ces défis conduisent à générer des données artificielles qui imitent les données du monde réel, qui peuvent être stockées sous forme de tableau structuré. Cela stimule la demande de données tabulaires, qui devrait croître avec un TCAC important au cours de la période de prévision. Des données tabulaires synthétiques peuvent être créées à l'aide du Generative Adversarial Network (GAN) pour aider les entreprises à améliorer la confidentialité et la sécurité des données opérationnelles.
Selon les analystes de recherche, l’utilisation de données tabulaires synthétiques pour former des modèles d’intelligence artificielle (IA) connaîtra une croissance environ trois fois plus rapide que les données structurées réelles d’ici 2030.
En outre, le segment des données textuelles devrait croître avec la plus grande part de marché en raison de l’utilisation croissante de systèmes de génération de langage naturel avec de nouveaux modèles d’apprentissage automatique.
Par analyse d'application
Besoin croissant de gestion des données de test par les gestionnaires de tests, contribuant à la croissance segmentaire
En fonction des applications, le marché est divisé en gestion des données de test, formation et développement de l’IA, partage de données d’entreprise, ainsi qu’analyse et visualisation des données. Le segment de la gestion des données de test détient la plus grande part de marché en raison du besoin croissant du plus petit ensemble de données par le gestionnaire de données de test pour les tests et le masquage des données. Il vise également à éviter les problèmes juridiques liés au RGPD.
Le segment du partage de données d'entreprise croît régulièrement à mesure que les entreprises sont confrontées à des difficultés lors du partage de données transfrontalier.
Par analyse de l’industrie
Pour savoir comment notre rapport peut optimiser votre entreprise, Parler à un analyste
L'industrie BFSI domine en raison de l'augmentation du nombre de cas de fraude et de l'utilisation du trading algorithmique
Sur la base de l'industrie, le marché est divisé en soins de santé, fabrication, médias et divertissement, automobile, BFSI, vente au détail et commerce électronique, informatique ettélécommunication, et d'autres. L'utilisation croissante de données synthétiques dans l'industrie BFSI contribue à améliorer la technique de détection des fraudes, l'analyse des risques et le trading algorithmique pour valider des structures de données complexes. Ainsi, le segment BFSI conduit à améliorer l’utilisation de données synthétiques pour offrir des expériences bancaires basées sur les données aux clients mondiaux. Le segment des soins de santé devrait dominer le marché, avec une contribution de 16 % à l’échelle mondiale en 2026.
De même, le segment des soins de santé arrive en deuxième position sur le marché, car l'utilisation croissante de données synthétiques dans le secteur de la santé permet de réaliser des essais cliniques, des recherches scientifiques, de générer des images médicales et de prédire des maladies rares. Ainsi, le segment des soins de santé croît avec le TCAC le plus élevé au cours de la période de prévision.
ANALYSE RÉGIONALE
North America Synthetic Data Generation Market Size, 2025 (USD Million)
Pour obtenir plus d'informations sur l'analyse régionale de ce marché, Télécharger un échantillon gratuit
La portée du marché mondial est classée dans cinq régions : Amérique du Nord, Europe, Asie-Pacifique, Moyen-Orient et Afrique, et Amérique du Sud.
Amérique du Nord
L'Amérique du Nord a dominé le marché avec une valorisation de 217,21 milliards USD en 2025 et de 284,77 milliards USD en 2026. L'Amérique du Nord détient la plus grande part de marché de la génération de données synthétiques, en raison de la présence de plusieurs acteurs du marché. Le nombre croissant de startups d’IA, d’instituts de recherche et d’entreprises de haute technologie génère une demande de données synthétiques de haute qualité pour mener des recherches et des expériences. Ce facteur alimente la croissance du marché dans toute la région.
Asie-Pacifique
L’Asie-Pacifique devrait connaître la croissance avec le TCAC le plus élevé au cours de la période de prévision. Cela est dû à la pénétration croissante de technologies avancées telles que l’IA/ML et à l’adoption croissante de services basés sur le cloud dans différents secteurs pour créer une infrastructure commerciale sécurisée. Augmenter les investissements dansIA générativeet l’intérêt croissant des entreprises pour la technologie de l’IA devrait stimuler la demande de processus de génération de données synthétiques en Asie-Pacifique au cours de la période de prévision.
Europe
L'Europe devrait connaître une croissance avec un TCAC important au cours de la période de prévision en raison de la présence de plusieurs fournisseurs de données synthétiques et d'une croissance considérable du financement des fournisseurs de données synthétiques structurées afin de permettre le développement des capacités internes de données synthétiques des organisations. Ce facteur devrait propulser la croissance du marché au cours de la période de prévision.
Pour savoir comment notre rapport peut optimiser votre entreprise, Parler à un analyste
Moyen-Orient, Afrique et Amérique du Sud
Le Moyen-Orient, l'Afrique et l'Amérique du Sud sont en croissance en raison de l'augmentationtransformation numériqueinitiatives dans les domaines du BFSI, de la santé, de l’automobile, ainsi que des médias et du divertissement. L’intégration des technologies d’intelligence artificielle et d’apprentissage automatique avec la finance et l’industrie automobile pour générer des données synthétiques fiables alimente la croissance du marché de la génération de données synthétiques dans les deux régions.
ACTEURS CLÉS DE L'INDUSTRIE
Les principaux acteurs se concentrent sur la génération de données synthétiques pour renforcer leur position
Les sociétés de génération de données synthétiques comprennent Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc. et K2view Ltd., entre autres. Les investissements croissants dans la génération de données synthétiques pour différents secteurs verticaux aident les principaux acteurs à maintenir leur avantage concurrentiel. Ces sociétés s'engagent également dans des partenariats stratégiques, des acquisitions et des collaborations pour étendre leur réseau commercial et de distribution et maintenir la croissance du marché.
Liste des entreprises clés profilées sur le marché de la génération de données synthétiques :
- Générateur de données(NOUS.)
- PRINCIPALEMENT AI (Autriche)
- TonicAI, Inc. (États-Unis)
- IA de synthèse (États-Unis)
- GenRocket, Inc. (États-Unis)
- Gretel Labs, Inc.(NOUS.)
- K2view Ltd.(Israël)
- Hazy Limité.(ROYAUME-UNI.)
- Replica Analytics Ltée. (Canada)
- YData Labs Inc. (États-Unis)
- Sogeti (France)
DÉVELOPPEMENTS CLÉS DE L’INDUSTRIE :
- Juin 2023 :Seeing Machine Limited a collaboré avec Devant AB, un fournisseur de données synthétiques centrées sur l'humain, pour améliorer la sécurité des transports en comprenant le comportement des conducteurs distraits. Ce partenariat a conduit à l'intégration de la nouvelle cabine du véhicule de Seeing Machine avec l'animation humaine 3D de Devant et les humains générés par ordinateur pour permettre le développement de la technologie de détection en cabine.
- Mai 2023 :Synthesis AI a lancé un nouvel ensemble de données synthétiques d'entreprise sur le marché Snowflake, où ses clients peuvent accéder aux visages humains synthétiques de Synthesis AI facilement disponibles pour développer des données visuelles pour le modèle de vision par ordinateur sans compromettre la vie privée des consommateurs de Synthesis AI.
- Décembre 2021 :Gretel.ai s'est associé à Illumina, Inc. pour fournir des données synthétiques pour la recherche en génomique et dans d'autres domaines connexes, notamment la biologie médico-légale, la biotechnologie et la systématique biologique, afin d'améliorer le développement de la médecine de précision.
- Mai 2021 :Parallel Domain, un fournisseur de plateforme de génération de données synthétiques, a lancé le premier visualiseur public de données synthétiques du secteur, qui aide les ingénieurs du secteur à interagir directement avec la caméra synthétique entièrement étiquetée et les ensembles de données LiDAR pour tester, déployer et former des solutions d'apprentissage automatique.
- Avril 2021 :Unity Software Inc. a lancé des ensembles de données d'images synthétiques pour développer des modèles d'intelligence artificielle de vision par ordinateur pouvant être utilisés à moindre coût dans les secteurs de l'architecture, de l'ingénierie et de la construction (AEC).
COUVERTURE DU RAPPORT
Le rapport fournit une analyse détaillée du marché et se concentre sur les aspects clés tels que les principales entreprises, les types de produits/services et les principales applications du produit. De plus, le rapport offre un aperçu des tendances du marché et met en évidence les principaux développements de l’industrie de la génération de données synthétiques. En plus des facteurs ci-dessus, le rapport englobe plusieurs facteurs qui ont contribué à la croissance du marché ces dernières années.
Demande de personnalisation pour acquérir une connaissance approfondie du marché.
Portée et segmentation du rapport
|
ATTRIBUT |
DÉTAILS |
|
Période d'études |
2021-2034 |
|
Année de référence |
2025 |
|
Année estimée |
2026 |
|
Période de prévision |
2026-2034 |
|
Période historique |
2021-2024 |
|
Taux de croissance |
TCAC de 31,1 % de 2026 à 2034 |
|
Unité |
Valeur (millions USD) |
|
Segmentation |
Par type de données, application, secteur d'activité et région |
|
Par type de données |
|
|
Par candidature |
|
|
Par industrie |
|
|
Par région |
|
Questions fréquentes
Le marché devrait atteindre 6 905,32 millions de dollars d’ici 2034.
En 2025, le marché était évalué à 603,61 millions de dollars.
Le marché devrait croître à un TCAC de 31,1 % au cours de la période de prévision.
Le segment des données de test devrait dominer le marché.
La demande croissante en matière de confidentialité et de sécurité des données pour alimenter la croissance du marché.
Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc., K2view Ltd., Sogeti et Hazy Limited sont les principaux acteurs du marché.
L’Amérique du Nord devrait détenir la part de marché la plus élevée.
Le segment des soins de santé devrait croître avec un TCAC remarquable au cours de la période de prévision.
Contactez nos experts Parlez à un expert



- 2021-2034
- 2025
- 2021-2024
- 160
Obtenez 30 à 60 heures de personnalisation gratuite
Ampliar a cobertura regional e por país, Análise de segmentos, Perfis de empresas, Benchmarking competitivo, e insights sobre o usuário final.
Rapports associés