Tamanho do mercado de geração de dados sintéticos, participação e análise do setor, por tipo de dados (dados de texto, dados de imagem e vídeo, dados tabulares e outros), por aplicação (gerenciamento de dados de teste, treinamento e desenvolvimento de IA, compartilhamento de dados empresariais e análise e visualização de dados), por setor (saúde, manufatura, mídia e entretenimento, automotivo, BFSI, varejo e comércio eletrônico, TI e telecomunicações e outros) e previsão regional, 2026-2034
PRINCIPAIS INFORMAÇÕES DE MERCADO
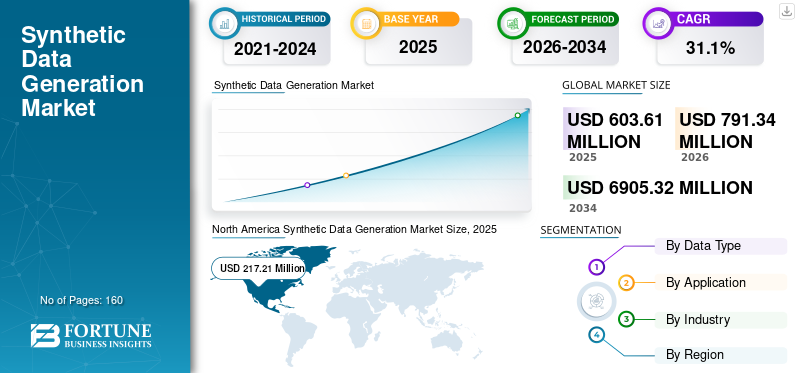
O tamanho global do mercado de geração de dados sintéticos foi avaliado em US$ 603,61 milhões em 2025. O mercado deve crescer de US$ 791,34 milhões em 2026 para US$ 6.905,32 milhões até 2034, exibindo um CAGR de 31,10% durante o período de previsão. A América do Norte dominou o mercado de geração de dados sintéticos com uma participação de mercado de 35,99% em 2025.
A geração de dados sintéticos é um processo por meio do qual os dados são criados de forma algorítmica ou artificial e não se baseiam em fenômenos do mundo real. Os dados sintéticos são uma versão distorcida dos dados originais que podem ser criados por meio de modelagem estatística e processos de simulação usando ferramentas adequadas e técnicas econômicas de aumento de dados.
De acordo com especialistas do setor, até 2024, quase 60% dos dados utilizados para desenvolver projetos de IA e análises serão gerados sinteticamente. Esses dados podem ser gerados usando vários métodos, incluindo simulações, amostragem estatística e Redes Adversariais Generativas (GAN) e são usados como um conjunto de dados de teste substituto para dados de produção ou operacionais para validar modelos matemáticos e treinar modelos de aprendizado de máquina. O processo de geração de dados sintéticos é útil quando a coleta de dados do mundo real é desafiadora ou impraticável.
Descarregue amostra grátis para saber mais sobre este relatório.
Conclusões do mercado de geração de dados sintéticos
- Tamanho do mercado em 2025: US$ 603,61 milhões
- Tamanho do mercado em 2026: US$ 791,34 milhões
- Tamanho do mercado previsto para 2034: US$ 6.905,32 milhões
- CAGR: 31,10% de 2026–2034
- A América do Norte dominou o mercado de geração de dados sintéticos com uma participação de 35,99% em 2025.
- O segmento de dados de texto deverá deter a maior participação de mercado durante o período de previsão.
- O segmento de gerenciamento de dados de teste foi responsável pela maior participação de mercado, enquanto o segmento de saúde deverá contribuir com 16% globalmente em 2026.
América do Norte
A América do Norte liderou o mercado global com uma avaliação de US$ 217,21 milhões em 2025 e deverá atingir US$ 284,77 milhões em 2026, impulsionada pela forte adoção de IA e análise de dados.
Europa
Espera-se que a Europa testemunhe um crescimento significativo, apoiado pelo aumento do financiamento para fornecedores de dados sintéticos e por avanços nas capacidades internas de dados sintéticos.
Ásia-Pacífico
Projeta-se que a Ásia-Pacífico registre a maior taxa de crescimento durante o período de previsão devido ao aumento dos investimentos em tecnologias de IA/ML e infraestrutura baseada em nuvem.
NÓS.
O mercado está experimentando um forte crescimento devido à ampla adoção de treinamento em IA, soluções de privacidade de dados e aplicativos de análise empresarial.
Japão
Espera-se que o mercado se beneficie dos crescentes investimentos em inovação em IA, iniciativas de transformação digital e do aumento da demanda por soluções seguras de compartilhamento de dados.
Leia mais
ÚLTIMAS TENDÊNCIAS
Aumento na implantação de grandes modelos de linguagem (LLM) para aumentar o crescimento do mercado
Large Language Models (LLM) são algoritmos de aprendizagem que ajudam a traduzir, gerar e prever texto e outros tipos de conteúdo com base em grandes conjuntos de dados e no desenvolvimento contínuo de sites e diversas soluções que utilizam modelos de linguagem. Generative Pre-trained Transformer (GPT) é um modelo de linguagem que gera dados de texto usando modelos GPT-1, GPT-2 e GPT-3. GPT-3 é o modelo mais complexo e atingiu 175 milhões de parâmetros de aprendizado de máquina para criar um grande conjunto de dados de conversação.
O desenvolvimento contínuo de websites e outras soluções de banco de dados aproveita a demanda por modelos de linguagem em vários setores, que incluem varejo, saúde, tecnologia e outros. Esses modelos de linguagem são usados por diferentes usuários finais para geração de texto, anotação de imagens, detecção de fraudes, IA conversacional e geração de código.
Assim, prevê-se que o aumento da implantação de Grandes Modelos de Linguagem (LLM) impulsione o crescimento do mercado durante o período de previsão.
Descarregue amostra grátis para saber mais sobre este relatório.
FATORES DE CRESCIMENTO DO MERCADO DE GERAÇÃO DE DADOS SINTÉTICOS
Crescente demanda por privacidade e segurança de dados para impulsionar o crescimento do mercado
Os dados do mundo real não podem ser acessados devido a questões de privacidade ou riscos de conformidade, juntamente com os regulamentos impostos pelo Regulamento Geral de Proteção de Dados (GDPR), pela Lei de Privacidade do Consumidor da Califórnia (CCPA) e pela Lei de Responsabilidade e Portabilidade de Seguros de Saúde (HIPAA). O aumento dos riscos de privacidade na recolha de conjuntos de dados do mundo real gera procura de dados sintéticos, uma versão realista do conjunto de dados reais com propriedades estatísticas semelhantes. Esses dados sintetizados podem ser usados como alternativa aos dados reais e oferecem diversas vantagens em relação à privacidade, escalabilidade e diversidade.
Por exemplo, em abril de 2023, a Betterdata, uma startup com sede em Singapura, declarou usar dados sintéticos com características e estrutura semelhantes aos conjuntos de dados do mundo real, sem divulgar informações confidenciais ou privadas de um indivíduo para proteger dados confidenciais e melhoraraprendizado de máquinamodelos.
FATORES DE RESTRIÇÃO
A falta de precisão e realismo dos dados dificulta o crescimento do mercado
A geração de dados sintéticos cria réplicas virtuais de conjuntos de dados que podem ser testados e compartilhados com os usuários. Além disso, este processo enfrenta dificuldade em capturar os mínimos detalhes de imagens do mundo real e modelos especializados.
Como os dados sintéticos dependem de dados do mundo real e de mudanças devido a inovações e desenvolvimentos, é um desafio manter o conjunto de dados sintéticos constante ao longo do tempo. Portanto, as organizações devem garantir regularmente a precisão e a confiabilidade dos dados sintéticos.
Este fator dificulta a precisão e o realismo dos dados sintéticos, dificultando significativamente o crescimento do mercado de geração de dados sintéticos.
ANÁLISE DE SEGMENTAÇÃO
Por análise de tipo de dados
Dados tabulares exibem CAGR proeminenteabordando questões de privacidade com dados artificiais
Com base no tipo de dados, o mercado é segmentado em dados de texto, dados de imagem e vídeo, dados tabulares, entre outros. Recentemente, as empresas têm enfrentado desafios na recolha de dados da vida real devido a questões de privacidade. Estes desafios levam à geração de dados artificiais que imitam dados do mundo real, que podem ser armazenados em formato tabular estruturado. Isso aumenta a demanda por dados tabulares, que deverá crescer com um CAGR proeminente durante o período de previsão. Dados tabulares sintéticos podem ser criados usando Generative Adversarial Network (GAN) para ajudar as empresas a melhorar a privacidade e segurança dos dados operacionais.
De acordo com analistas de pesquisa, o uso de dados tabulares sintéticos para treinar modelos de Inteligência Artificial (IA) crescerá aproximadamente três vezes mais rápido do que dados estruturados reais até 2030.
Além disso, prevê-se que o segmento de dados de texto cresça com a maior participação de mercado devido ao aumento do uso de sistemas de geração de linguagem natural com novos modelos de aprendizado de máquina.
Por análise de aplicação
Necessidade crescente de gerenciamento de dados de teste por parte dos gerentes de teste, contribuindo para o crescimento segmental
Com base na aplicação, o mercado é dividido em gerenciamento de dados de teste, treinamento e desenvolvimento de IA, compartilhamento de dados corporativos e análise e visualização de dados. O segmento de gerenciamento de dados de teste detém a maior participação de mercado devido à crescente necessidade do menor conjunto de dados pelo gerenciador de dados de teste para teste e mascaramento de dados. Também visa evitar problemas jurídicos associados ao GDPR.
O segmento de partilha de dados empresariais cresce constantemente à medida que as empresas enfrentam dificuldades durante a partilha de dados transfronteiriços.
Por análise da indústria
Para saber como nosso relatório pode ajudar a otimizar seu negócio, Fale com um analista
A indústria BFSI domina devido ao aumento do número de casos de fraude e ao uso de negociação algorítmica
Com base na indústria, o mercado é dividido em saúde, manufatura, mídia e entretenimento, automotivo, BFSI, varejo e e-commerce, TI etelecomunicaçãoe outros. O aumento do uso de dados sintéticos em toda a indústria BFSI ajuda a aprimorar a técnica de detecção de fraudes, a análise de risco e a negociação algorítmica para validar estruturas de dados complexas. Assim, o segmento BFSI leva ao aprimoramento do uso de dados sintéticos para fornecer experiências bancárias baseadas em dados a clientes globais. Espera-se que o segmento de saúde lidere o mercado, contribuindo com 16% globalmente em 2026.
Da mesma forma, o segmento de saúde lidera com a segunda posição no mercado, já que o aumento do uso de dados sintéticos no setor de saúde ajuda a realizar ensaios clínicos, pesquisas científicas, gerar imagens médicas e prever doenças raras. Assim, o segmento de saúde cresce com maior CAGR durante o período de previsão.
ANÁLISE REGIONAL
North America Synthetic Data Generation Market Size, 2025 (USD Million)
Para obter mais informações sobre a análise regional deste mercado, Descarregue amostra grátis
O escopo do mercado global é classificado em cinco regiões, América do Norte, Europa, Ásia-Pacífico, Oriente Médio e África e América do Sul.
América do Norte
A América do Norte dominou o mercado com uma avaliação de US$ 217,21 bilhões em 2025 e US$ 284,77 bilhões em 2026. A América do Norte detém a maior participação no mercado de geração de dados sintéticos, devido à presença de vários participantes do mercado. O número crescente de startups de IA, institutos de pesquisa e empresas de alta tecnologia gera demanda por dados sintéticos de alta qualidade para a realização de pesquisas e experimentos. Esse fator alimenta o crescimento do mercado em toda a região.
Ásia-Pacífico
Espera-se que a Ásia-Pacífico cresça com o maior CAGR durante o período de previsão. Isso se deve à crescente penetração de tecnologias avançadas, como IA/ML, e à crescente adoção de serviços baseados em nuvem entre diferentes setores para construir infraestruturas empresariais seguras. Aumentar o investimento emIA generativae prevê-se que o foco crescente das empresas na tecnologia de IA impulsione a demanda por processos de geração de dados sintéticos na Ásia-Pacífico durante o período de previsão.
Europa
Espera-se que a Europa cresça com um CAGR significativo durante o período de previsão devido à presença de vários fornecedores de dados sintéticos e ao enorme crescimento no financiamento para fornecedores de dados sintéticos estruturados para trazer desenvolvimentos nas capacidades internas de dados sintéticos das organizações. Projeta-se que esse fator impulsione o crescimento do mercado durante o período de previsão.
Para saber como nosso relatório pode ajudar a otimizar seu negócio, Fale com um analista
Oriente Médio e África e América do Sul
O Médio Oriente, África e América do Sul estão a crescer devido ao aumentotransformação digitaliniciativas em BFSI, saúde, automotivo e mídia e entretenimento. A integração da inteligência artificial e das tecnologias de aprendizagem automática com as finanças e a indústria automóvel para gerar dados sintéticos fiáveis alimenta o crescimento do mercado de geração de dados sintéticos em ambas as regiões.
PRINCIPAIS ATORES DA INDÚSTRIA
Os principais participantes se concentram na geração de dados sintéticos para fortalecer sua posição
As empresas de geração de dados sintéticos incluem Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc. e K2view Ltd., entre outras. O aumento dos investimentos na geração de dados sintéticos para diferentes setores verticais da indústria está ajudando os principais participantes a manterem sua vantagem competitiva. Essas empresas também se envolvem em parcerias estratégicas, aquisições e colaborações para expandir seus negócios e rede de distribuição e manter o crescimento do mercado.
Lista das principais empresas perfiladas no mercado de geração de dados sintéticos:
- Datagen(NÓS.)
- PRINCIPALMENTE AI (Áustria)
- (EUA)
- Síntese AI (EUA)
- GenRocket, Inc.
- Gretel Labs, Inc.(NÓS.)
- K2view Ltd.(Israel)
- Nebuloso Limitado.(REINO UNIDO.)
- Replica Analytics Ltd. (Canadá)
- YData Labs Inc.
- Sogeti (França)
PRINCIPAIS DESENVOLVIMENTOS DA INDÚSTRIA:
- Junho de 2023:A Seeing Machine Limited colaborou com a Devant AB, um fornecedor de dados sintéticos centrados no ser humano, para melhorar a segurança do transporte através da compreensão do comportamento distraído do condutor. Esta parceria levou à integração da nova cabine do veículo da Seeing Machine com a animação humana 3D da Devant e seres humanos gerados por computador para trazer o desenvolvimento da tecnologia de detecção na cabine.
- Maio de 2023:A Synthesis AI lançou um novo conjunto de dados sintéticos empresariais no mercado Snowflake, onde seus clientes podem acessar rostos humanos sintéticos da Synthesis AI prontamente disponíveis para desenvolver dados visuais para o modelo de visão computacional sem comprometer a privacidade do consumidor da Synthesis AI.
- Dezembro de 2021:Gretel.ai fez parceria com a Illumina, Inc. para fornecer dados sintéticos para pesquisas em genômica e outras áreas relacionadas, incluindo biologia forense, biotecnologia e sistemática biológica para aprimorar o desenvolvimento da medicina de precisão.
- Maio de 2021:A Parallel Domain, fornecedora de plataforma de geração de dados sintéticos, lançou o primeiro visualizador público de dados sintéticos do setor, que ajuda os engenheiros do setor a interagir diretamente com a câmera sintética totalmente rotulada e os conjuntos de dados LiDAR para testar, implantar e treinar soluções de aprendizado de máquina.
- Abril de 2021:lançou conjuntos de dados de imagens sintéticas para desenvolver modelos de inteligência artificial de visão computacional que podem ser usados a custos mais baixos nos setores de Arquitetura, Engenharia e Construção (AEC).
COBERTURA DO RELATÓRIO
O relatório fornece uma análise detalhada do mercado e concentra-se em aspectos-chave, como empresas líderes, tipos de produtos/serviços e principais aplicações do produto. Além disso, o relatório oferece insights sobre as tendências do mercado e destaca os principais desenvolvimentos da indústria de geração de dados sintéticos. Além dos fatores acima, o relatório abrange diversos fatores que contribuíram para o crescimento do mercado nos últimos anos.
Pedido de Personalização Para obter informações abrangentes sobre o mercado.
Escopo e segmentação do relatório
|
ATRIBUTO |
DETALHES |
|
Período de estudo |
2021-2034 |
|
Ano base |
2025 |
|
Ano estimado |
2026 |
|
Período de previsão |
2026-2034 |
|
Período Histórico |
2021-2024 |
|
Taxa de crescimento |
CAGR de 31,1% de 2026 a 2034 |
|
Unidade |
Valor (US$ milhões) |
|
Segmentação |
Por tipo de dados, aplicativo, setor e região |
|
Por tipo de dados |
|
|
Por aplicativo |
|
|
Por indústria |
|
|
Por região |
|
Perguntas Frequentes
O mercado está projetado para atingir US$ 6.905,32 milhões até 2034.
Em 2025, o mercado foi avaliado em US$ 603,61 milhões.
O mercado deverá crescer a um CAGR de 31,1% durante o período de previsão.
Espera-se que o segmento de dados de teste lidere o mercado.
A crescente demanda por privacidade e segurança de dados para alimentar o crescimento do mercado.
Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc., K2view Ltd., Sogeti e Hazy Limited são os principais players do mercado.
Espera-se que a América do Norte detenha a maior participação de mercado.
Espera-se que o segmento de saúde cresça com um CAGR notável durante o período de previsão.
Entre em contacto com os nossos especialistas Fale com um especialista



- 2021-2034
- 2025
- 2021-2024
- 160
Receba de 30 a 60 horas de personalização gratuita
Ampliar a cobertura regional e por país, Análise de segmentos, Perfis de empresas, Benchmarking competitivo, e insights sobre o usuário final.
Relatórios relacionados
-
US +1 833 909 2966 (chamada gratuita)
-
Entre em contacto connosco