合成数据生成市场规模、份额和行业分析,按数据类型(文本数据、图像和视频数据、表格数据等)、按应用(测试数据管理、人工智能培训和开发、企业数据共享以及数据分析和可视化)、按行业(医疗保健、制造、媒体和娱乐、汽车、BFSI、零售和电子商务、IT 和电信等)以及区域预测,2026-2034 年
主要市场见解
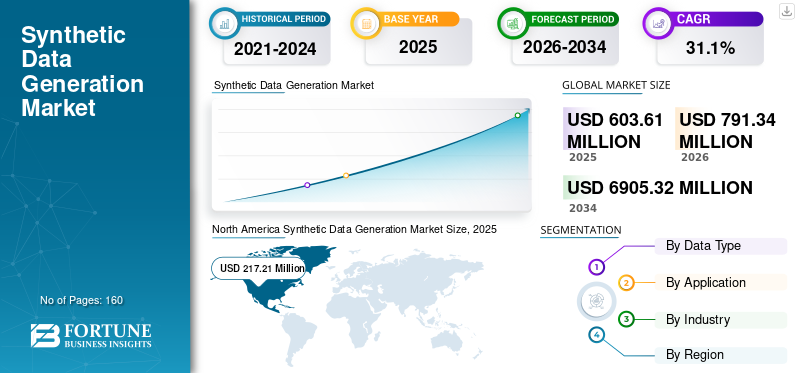
2025年,全球合成数据生成市场规模为6.0361亿美元。预计该市场将从2026年的7.9134亿美元增长到2034年的69.0532亿美元,预测期内复合年增长率为31.10%。北美在合成数据生成市场占据主导地位,2025 年市场份额为 35.99%。
合成数据生成是通过算法或人工创建数据的过程,而不是基于现实世界的现象。合成数据是原始数据的扭曲版本,可以使用适当的工具和经济有效的数据增强技术通过统计建模和模拟过程创建。
据行业专家称,到 2024 年,用于开发人工智能和分析项目的近 60% 的数据将是综合生成的。该数据可以使用各种方法生成,包括模拟、统计采样和生成对抗网络 (GAN),并用作生产或运营数据的替代测试数据集,以验证数学模型和训练机器学习模型。当收集现实世界的数据具有挑战性或不切实际时,合成数据生成过程会很有帮助。
下载免费样品 了解更多关于本报告的信息。
综合数据生成市场要点
- 2025年市场规模:6.0361亿美元
- 2026年市场规模:7.9134亿美元
- 2034 年预测市场规模:690532 万美元
- 复合年增长率:2026-2034 年 31.10%
- 到 2025 年,北美将占据合成数据生成市场的 35.99% 份额。
- 预计文本数据领域将在预测期内占据最大的市场份额。
- 测试数据管理领域占据最大的市场份额,而医疗保健领域预计到2026年将在全球贡献16%的份额。
北美
北美在人工智能和数据分析强劲采用的推动下,2025 年估值为 2.1721 亿美元,引领全球市场,预计 2026 年将达到 2.8477 亿美元。
欧洲
在合成数据供应商资金增加和内部合成数据能力进步的支持下,欧洲预计将出现显着增长。
亚太地区
由于人工智能/机器学习技术和基于云的基础设施的投资不断增加,预计亚太地区在预测期内将实现最高的增长率。
我们。
由于人工智能培训、数据隐私解决方案和企业分析应用程序的广泛采用,该市场正在经历强劲增长。
日本
市场预计将受益于人工智能创新、数字化转型计划不断增长的投资以及对安全数据共享解决方案不断增长的需求。
阅读更多
最新趋势
大型语言模型 (LLM) 的部署激增以促进市场增长
大型语言模型 (LLM) 是一种学习算法,可帮助基于大型数据集以及网站和使用语言模型的各种解决方案的持续开发来翻译、生成和预测文本及其他类型的内容。生成式预训练 Transformer (GPT) 是一种使用 GPT-1、GPT-2 和 GPT-3 模型生成文本数据的语言模型。 GPT-3 是最复杂的模型,已达到 1.75 亿个机器学习参数,可创建大型会话数据集。
网站和其他数据库解决方案的不断发展利用了各个行业对语言模型的需求,包括零售、医疗保健、科技等。这些语言模型被不同的最终用户用于文本生成、图像注释、欺诈检测、对话式人工智能和代码生成。
因此,大型语言模型(LLM)部署的增加预计将在预测期内推动市场增长。
下载免费样品 了解更多关于本报告的信息。
合成数据生成市场增长因素
对数据隐私和安全的需求不断增长,推动市场增长
由于隐私问题或合规风险以及《通用数据保护条例》(GDPR)、《加州消费者隐私法案》(CCPA) 和《健康保险流通与责任法案》(HIPAA) 规定的规定,无法访问真实世界的数据。收集真实世界数据集的隐私风险的上升产生了对合成数据的需求,合成数据是具有类似统计特性的真实数据集的现实版本。这种合成数据可以用作真实数据的替代品,并在隐私性、可扩展性和多样性方面提供多种优势。
例如,2023 年 4 月,新加坡初创公司 Betterdata 宣布使用与现实世界数据集具有相似特征和结构的合成数据,而不泄露个人的敏感或私人信息,以保护机密数据并增强数据安全性。机器学习模型。
制约因素
缺乏数据准确性和现实性阻碍了市场增长
合成数据生成创建可以测试并与用户共享的数据集的虚拟副本。此外,这个过程面临着捕捉现实世界图像和专业模型的微小细节的困难。
由于合成数据依赖于现实世界的数据以及由于创新和发展而发生的变化,因此保持合成数据集随着时间的推移保持恒定是具有挑战性的。因此,组织应定期确保合成数据的准确性和可靠性。
这一因素阻碍了合成数据的准确性和真实性,极大地阻碍了合成数据生成市场的增长。
细分分析
按数据类型分析
表格数据显示出显着的复合年增长率通过人工数据解决隐私问题
根据数据类型,市场分为文本数据、图像和视频数据、表格数据等。最近,由于隐私问题,公司在收集现实生活数据方面面临挑战。这些挑战导致生成模仿现实世界数据的人工数据,这些数据可以以结构化表格格式存储。这增加了对表格数据的需求,预计在预测期内将以显着的复合年增长率增长。可以使用生成对抗网络 (GAN) 创建合成表格数据,以帮助企业增强运营数据的隐私和安全性。
研究分析师表示,到 2030 年,使用合成表格数据训练人工智能 (AI) 模型的增长速度将比真实结构化数据快约三倍。
此外,由于自然语言生成系统和新机器学习模型的使用不断增加,文本数据领域预计将以最大的市场份额增长。
按应用分析
测试经理对测试数据管理的需求不断增加,有助于细分市场的增长
根据应用,市场分为测试数据管理、人工智能培训和开发、企业数据共享以及数据分析和可视化。由于测试数据管理器对数据测试和数据屏蔽的最小数据集的需求不断增加,测试数据管理领域占据了最大的市场份额。它还旨在避免与 GDPR 相关的法律问题。
企业数据共享领域稳步增长,企业跨境数据共享面临困难。
按行业分析
了解我们的报告如何帮助优化您的业务, 与分析师交流
由于欺诈案件数量和算法交易使用的增加,BFSI 行业占据主导地位
根据行业,市场分为医疗保健、制造、媒体和娱乐、汽车、BFSI、零售和电子商务、IT 和电信,以及其他。 BFSI 行业越来越多地使用合成数据有助于增强欺诈检测技术、风险分析和算法交易,以验证复杂的数据结构。因此,BFSI 部门可以增强合成数据的使用,为全球客户提供数据驱动的银行体验。医疗保健领域预计将引领市场,到 2026 年将占全球市场的 16%。
同样,医疗保健领域在市场上排名第二,因为医疗保健行业越来越多地使用合成数据有助于进行临床试验、科学研究、生成医学图像和预测罕见疾病。因此,医疗保健领域在预测期内以最高的复合年增长率增长。
区域分析
North America Synthetic Data Generation Market Size, 2025 (USD Million)
获取本市场区域分析的更多信息, 下载免费样品
全球市场范围分为北美、欧洲、亚太、中东和非洲、南美五个地区。
北美
北美以 2025 年 2172.1 亿美元的估值和 2026 年 2847.7 亿美元的估值主导市场。由于存在多个市场参与者,北美拥有最大的合成数据生成市场份额。人工智能初创公司、研究机构和高科技公司数量的不断增加产生了对高质量合成数据进行研究和实验的需求。这一因素推动了整个地区的市场增长。
亚太地区
预计亚太地区在预测期内将以最高的复合年增长率增长。这是由于人工智能/机器学习等先进技术的渗透率不断提高,以及不同行业越来越多地采用基于云的服务来构建安全的业务基础设施。加大投资力度生成式人工智能预计公司对人工智能技术的日益关注将在预测期内推动亚太地区对合成数据生成流程的需求。
欧洲
由于存在多个合成数据供应商,并且结构化合成数据供应商的资金大幅增长,以促进组织内部合成数据能力的发展,预计欧洲在预测期内将以显着的复合年增长率增长。预计这一因素将在预测期内推动市场增长。
了解我们的报告如何帮助优化您的业务, 与分析师交流
中东、非洲和南美洲
中东、非洲和南美洲的增长是由于数字化转型BFSI、医疗保健、汽车以及媒体和娱乐领域的举措。将人工智能和机器学习技术与金融和汽车行业相结合,生成可靠的合成数据,推动了这两个地区合成数据生成市场的增长。
主要行业参与者
主要参与者专注于生成综合数据以巩固其地位
合成数据生成公司包括 Datagen、MOSTLY AI、TonicAI, Inc.、Synthesis AI、GenRocket, Inc.、Gretel Labs, Inc. 和 K2view Ltd. 等。增加对不同垂直行业合成数据生成的投资正在帮助关键参与者保持竞争优势。这些公司还参与战略合作伙伴关系、收购和合作,以扩大其业务和分销网络并保持市场增长。
合成数据生成市场的主要公司名单:
- 数据生成器(我们。)
- 主要是人工智能(奥地利)
- TonicAI, Inc.(美国)
- 综合人工智能(美国)
- GenRocket, Inc.(美国)
- 格蕾特实验室公司(我们。)
- K2view有限公司(以色列)
- 朦胧有限公司。(英国。)
- 复制分析有限公司(加拿大)
- YData Labs Inc.(美国)
- 索盖蒂(法国)
主要行业发展:
- 2023 年 6 月:Seeing Machine Limited 与以人为本的合成数据提供商 Devant AB 合作,通过了解驾驶员分心的行为来提高交通安全。此次合作将 Seeing Machine 的新型车厢与 Devant 的 3D 人体动画和计算机生成的人体相结合,从而推动了车厢内传感技术的发展。
- 2023 年 5 月:Synthesis AI 在 Snowflake 市场上推出了一个新的企业合成数据集,客户可以访问现成的 Synthesis AI 的合成人脸,为计算机视觉模型开发视觉数据,而不会损害 Synthesis AI 的消费者隐私。
- 2021 年 12 月:Gretel.ai 与 Illumina, Inc. 合作,为基因组学和其他相关领域(包括法医生物学、生物技术和生物系统学)的研究提供合成数据,以促进精准医学的发展。
- 2021 年 5 月:合成数据生成平台提供商 Parallel Domain 推出了业界首个公共合成数据可视化工具,帮助行业工程师直接与完全标记的合成相机和 LiDAR 数据集进行交互,以测试、部署和训练机器学习解决方案。
- 2021 年 4 月:Unity Software Inc. 推出了合成图像数据集,用于开发计算机视觉人工智能模型,可以以较低的成本在建筑、工程和施工 (AEC) 行业中使用。
报告范围
该报告对市场进行了详细分析,重点关注领先企业、产品/服务类型、产品领先应用等关键方面。此外,该报告还提供了对市场趋势的见解,并重点介绍了合成数据生成行业的关键发展。除了上述因素外,报告还涵盖了近年来促进市场增长的几个因素。
定制请求 获取广泛的市场洞察。
报告范围和细分
|
属性 |
细节 |
|
学习期限 |
2021-2034 |
|
基准年 |
2025年 |
|
预计年份 |
2026年 |
|
预测期 |
2026-2034 |
|
历史时期 |
2021-2024 |
|
增长率 |
2026年至2034年复合年增长率为31.1% |
|
单元 |
价值(百万美元) |
|
分割 |
按数据类型、应用、行业和地区 |
|
按数据类型 |
|
|
按申请 |
|
|
按行业分类 |
|
|
按地区 |
|
常见问题
预计到 2034 年,市场规模将达到 690532 万美元。
2025年,市场价值为6.0361亿美元。
预计该市场在预测期内将以 31.1% 的复合年增长率增长。
测试数据部分预计将引领市场。
对数据隐私和安全的需求不断增长,推动了市场增长。
Datagen、MOSTLY AI、TonicAI, Inc.、Synthesis AI、GenRocket, Inc.、Gretel Labs, Inc.、K2view Ltd.、Sogeti 和 Hazy Limited 是市场上的顶级参与者。
预计北美将占据最高的市场份额。
预计医疗保健领域在预测期内将以显着的复合年增长率增长。
与我们的专家联系 与专家交谈



- 2021-2034
- 2025
- 2021-2024
- 160
获得30至60小时免费定制服务
扩大区域和国家覆盖范围, 细分市场分析, 公司简介, 竞争基准分析, 以及最终用户洞察。