Marktgröße, Anteil und Branchenanalyse für die Generierung synthetischer Daten, nach Datentyp (Textdaten, Bild- und Videodaten, Tabellendaten und andere), nach Anwendung (Testdatenmanagement, KI-Schulung und -Entwicklung, Unternehmensdatenfreigabe und Datenanalyse und -visualisierung), nach Branche (Gesundheitswesen, Fertigung, Medien und Unterhaltung, Automobil, BFSI, Einzelhandel und E-Commerce, IT und Telekommunikation und andere) und regionale Prognose, 2026–2034
WICHTIGE MARKTEINBLICKE
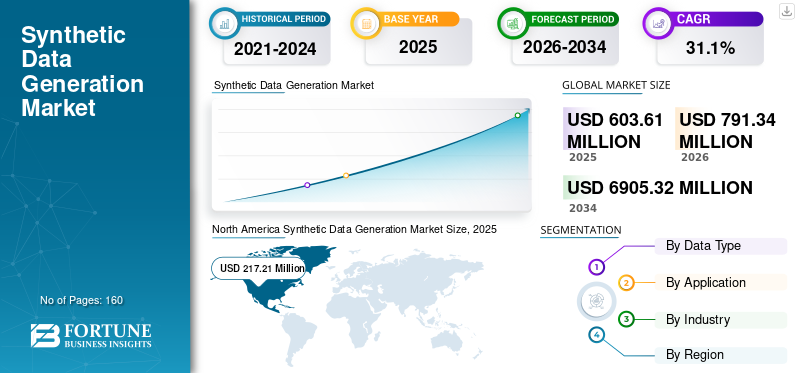
Die globale Marktgröße für die Generierung synthetischer Daten wurde im Jahr 2025 auf 603,61 Millionen US-Dollar geschätzt. Der Markt wird voraussichtlich von 791,34 Millionen US-Dollar im Jahr 2026 auf 6905,32 Millionen US-Dollar im Jahr 2034 wachsen und im Prognosezeitraum eine jährliche Wachstumsrate von 31,10 % aufweisen. Nordamerika dominierte den Markt für die Generierung synthetischer Daten mit einem Marktanteil von 35,99 % im Jahr 2025.
Bei der Generierung synthetischer Daten handelt es sich um einen Prozess, bei dem Daten algorithmisch oder künstlich erstellt werden und der nicht auf realen Phänomenen basiert. Synthetische Daten sind eine verzerrte Version der Originaldaten, die durch statistische Modellierungs- und Simulationsprozesse unter Verwendung geeigneter Tools und kostengünstiger Datenerweiterungstechniken erstellt werden können.
Laut Branchenexperten werden bis 2024 fast 60 % der für die Entwicklung von KI- und Analyseprojekten verwendeten Daten synthetisch generiert werden. Diese Daten können mit verschiedenen Methoden generiert werden, darunter Simulationen, statistische Stichproben und Generative Adversarial Networks (GAN), und werden als Ersatztestdatensatz für Produktions- oder Betriebsdaten verwendet, um mathematische Modelle zu validieren und Modelle für maschinelles Lernen zu trainieren. Der Prozess der Generierung synthetischer Daten ist hilfreich, wenn die Erfassung realer Daten schwierig oder unpraktisch ist.
Laden Sie ein kostenloses Muster herunter um mehr über diesen Bericht zu erfahren.
Erkenntnisse zum Markt für synthetische Datengenerierung
- Marktgröße 2025: 603,61 Millionen US-Dollar
- Marktgröße 2026: 791,34 Millionen US-Dollar
- Prognostizierte Marktgröße 2034: 6.905,32 Millionen US-Dollar
- CAGR: 31,10 % von 2026–2034
- Nordamerika dominierte den Markt für die Generierung synthetischer Daten mit einem Anteil von 35,99 % im Jahr 2025.
- Das Textdatensegment dürfte im Prognosezeitraum den größten Marktanteil halten.
- Das Segment Testdatenmanagement hatte den größten Marktanteil, während das Gesundheitssegment im Jahr 2026 weltweit voraussichtlich 16 % beitragen wird.
Nordamerika
Nordamerika führte den Weltmarkt mit einer Bewertung von 217,21 Millionen US-Dollar im Jahr 2025 an und wird voraussichtlich im Jahr 2026 284,77 Millionen US-Dollar erreichen, angetrieben durch die starke Einführung von KI und Datenanalysen.
Europa
Es wird erwartet, dass Europa ein erhebliches Wachstum verzeichnen wird, das durch die zunehmende Finanzierung von Anbietern synthetischer Daten und Fortschritte bei den internen Kapazitäten für synthetische Daten unterstützt wird.
Asien-Pazifik
Der Asien-Pazifik-Raum dürfte im Prognosezeitraum aufgrund steigender Investitionen in KI/ML-Technologien und cloudbasierte Infrastruktur die höchste Wachstumsrate verzeichnen.
UNS.
Der Markt verzeichnet aufgrund der weit verbreiteten Einführung von KI-Schulungen, Datenschutzlösungen und Unternehmensanalyseanwendungen ein starkes Wachstum.
Japan
Es wird erwartet, dass der Markt von wachsenden Investitionen in KI-Innovationen, Initiativen zur digitalen Transformation und der steigenden Nachfrage nach sicheren Lösungen für den Datenaustausch profitieren wird.
Mehr lesen
NEUESTE TRENDS
Anstieg der Bereitstellung großer Sprachmodelle (LLM) zur Steigerung des Marktwachstums
Large Language Models (LLM) sind Lernalgorithmen, die dabei helfen, Text und andere Arten von Inhalten zu übersetzen, zu generieren und vorherzusagen, basierend auf großen Datensätzen und der kontinuierlichen Entwicklung von Websites und verschiedenen Lösungen, die Sprachmodelle verwenden. Generative Pre-trained Transformer (GPT) ist ein Sprachmodell, das Textdaten mithilfe der Modelle GPT-1, GPT-2 und GPT-3 generiert. GPT-3 ist das komplexeste Modell und hat 175 Millionen Parameter für maschinelles Lernen erreicht, um einen großen Datensatz an Konversationsdaten zu erstellen.
Die kontinuierliche Weiterentwicklung von Websites und anderen Datenbanklösungen steigert die Nachfrage nach Sprachmodellen in verschiedenen Branchen, darunter Einzelhandel, Gesundheitswesen, Technologie und andere. Diese Sprachmodelle werden von verschiedenen Endbenutzern zur Textgenerierung, Bildanmerkung, Betrugserkennung, Konversations-KI und Codegenerierung verwendet.
Daher wird erwartet, dass der zunehmende Einsatz von Large Language Models (LLM) das Marktwachstum im Prognosezeitraum vorantreiben wird.
Laden Sie ein kostenloses Muster herunter um mehr über diesen Bericht zu erfahren.
Wachstumsfaktoren für synthetische Datengenerierung
Wachsende Nachfrage nach Datenschutz und Sicherheit zur Förderung des Marktwachstums
Aufgrund von Datenschutzbedenken oder Compliance-Risiken sowie den Vorschriften der Datenschutz-Grundverordnung (DSGVO), des California Consumer Privacy Act (CCPA) und des Health Insurance Portability and Accountability Act (HIPAA) ist der Zugriff auf reale Daten nicht möglich. Der Anstieg der Datenschutzrisiken bei der Erfassung realer Datensätze führt zu einer Nachfrage nach synthetischen Daten, einer realistischen Version des realen Datensatzes mit ähnlichen statistischen Eigenschaften. Diese synthetisierten Daten können als Alternative zu echten Daten verwendet werden und bieten mehrere Vorteile hinsichtlich Datenschutz, Skalierbarkeit und Vielfalt.
Beispielsweise erklärte Betterdata, ein in Singapur ansässiges Startup, im April 2023, dass es synthetische Daten verwenden werde, die ähnliche Eigenschaften und Strukturen wie reale Datensätze aufweisen, ohne sensible oder private Informationen einer Person preiszugeben, um vertrauliche Daten zu schützen und zu verbessernmaschinelles LernenModelle.
EINHALTENDE FAKTOREN
Mangelnde Datengenauigkeit und -realismus behindern das Marktwachstum
Durch die synthetische Datengenerierung werden virtuelle Replikate von Datensätzen erstellt, die getestet und mit Benutzern geteilt werden können. Darüber hinaus ist es bei diesem Prozess schwierig, die kleinsten Details realer Bilder und spezieller Modelle zu erfassen.
Da synthetische Daten von realen Daten und Änderungen aufgrund von Innovationen und Entwicklungen abhängen, ist es eine Herausforderung, den synthetischen Datensatz über die Zeit konstant zu halten. Daher sollten Organisationen regelmäßig die Genauigkeit und Zuverlässigkeit der synthetischen Daten sicherstellen.
Dieser Faktor beeinträchtigt die Genauigkeit und den Realismus der synthetischen Daten und behindert das Wachstum des Marktes für die Generierung synthetischer Daten erheblich.
SEGMENTIERUNGSANALYSE
Nach Datentypanalyse
Tabellarische Daten weisen eine herausragende CAGR aufindem wir Datenschutzbedenken mit künstlichen Daten ansprechen
Basierend auf dem Datentyp wird der Markt in Textdaten, Bild- und Videodaten, Tabellendaten und andere segmentiert. In letzter Zeit stehen Unternehmen aufgrund von Datenschutzbedenken vor der Herausforderung, reale Daten zu sammeln. Diese Herausforderungen führen zur Generierung künstlicher Daten, die reale Daten nachahmen und in einem strukturierten Tabellenformat gespeichert werden können. Dies steigert die Nachfrage nach tabellarischen Daten, die im Prognosezeitraum voraussichtlich mit einer deutlichen CAGR wachsen wird. Mithilfe des Generative Adversarial Network (GAN) können synthetische Tabellendaten erstellt werden, um Unternehmen bei der Verbesserung des betrieblichen Datenschutzes und der Sicherheit zu unterstützen.
Forschungsanalysten zufolge wird die Verwendung synthetischer Tabellendaten zum Trainieren von Modellen der künstlichen Intelligenz (KI) bis 2030 etwa dreimal schneller zunehmen als echte strukturierte Daten.
Darüber hinaus wird erwartet, dass das Textdatensegment aufgrund der zunehmenden Nutzung von Systemen zur Erzeugung natürlicher Sprache mit neuen Modellen des maschinellen Lernens mit dem größten Marktanteil wachsen wird.
Durch Anwendungsanalyse
Steigender Bedarf an Testdatenmanagement durch Testmanager trägt zum Segmentwachstum bei
Basierend auf der Anwendung ist der Markt in Testdatenmanagement, KI-Schulung und -Entwicklung, Unternehmensdatenaustausch sowie Datenanalyse und -visualisierung unterteilt. Das Segment Testdatenmanagement hält den größten Marktanteil, da der Testdatenmanager für Datentests und Datenmaskierung zunehmend den kleinsten Datensatz benötigt. Ziel ist es auch, rechtliche Probleme im Zusammenhang mit der DSGVO zu vermeiden.
Das Segment der Unternehmensdatenfreigabe wächst stetig, da Unternehmen beim grenzüberschreitenden Datenaustausch auf Schwierigkeiten stoßen.
Nach Branchenanalyse
Erfahren Sie, wie unser Bericht Ihr Geschäft optimieren kann, Sprechen Sie mit einem Analysten
Die BFSI-Branche dominiert aufgrund der steigenden Zahl von Betrugsfällen und der Nutzung von algorithmischem Handel
Auf der Grundlage der Branche ist der Markt in Gesundheitswesen, Fertigung, Medien und Unterhaltung, Automobil, BFSI, Einzelhandel und E-Commerce, IT undTelekommunikation, und andere. Die zunehmende Nutzung synthetischer Daten in der gesamten BFSI-Branche trägt dazu bei, die Betrugserkennungstechnik, die Risikoanalyse und den algorithmischen Handel zur Validierung komplexer Datenstrukturen zu verbessern. Somit führt das BFSI-Segment dazu, die Nutzung synthetischer Daten zu verbessern, um globalen Kunden datengesteuerte Bankerlebnisse zu bieten. Es wird erwartet, dass das Gesundheitssegment mit einem weltweiten Beitrag von 16 % im Jahr 2026 den Markt anführen wird.
Ebenso ist das Gesundheitssegment mit dem zweiten Platz im Markt führend, da die zunehmende Nutzung synthetischer Daten in der Gesundheitsbranche dazu beiträgt, klinische Studien und wissenschaftliche Forschung durchzuführen, medizinische Bilder zu erstellen und seltene Krankheiten vorherzusagen. Somit wächst das Gesundheitssegment im Prognosezeitraum mit der höchsten CAGR.
REGIONALE ANALYSE
North America Synthetic Data Generation Market Size, 2025 (USD Million)
Um weitere Informationen zur regionalen Analyse dieses Marktes zu erhalten, Laden Sie ein kostenloses Beispiel herunter
Der globale Marktumfang ist in fünf Regionen unterteilt: Nordamerika, Europa, Asien-Pazifik, Naher Osten und Afrika sowie Südamerika.
Nordamerika
Nordamerika dominierte den Markt mit einer Bewertung von 217,21 Milliarden US-Dollar im Jahr 2025 und 284,77 Milliarden US-Dollar im Jahr 2026. Nordamerika hält aufgrund der Präsenz mehrerer Marktteilnehmer den größten Marktanteil bei der Generierung synthetischer Daten. Die steigende Zahl von KI-Startups, Forschungsinstituten und High-Tech-Unternehmen erzeugt eine Nachfrage nach hochwertigen synthetischen Daten für die Durchführung von Forschung und Experimenten. Dieser Faktor fördert das Marktwachstum in der gesamten Region.
Asien-Pazifik
Es wird erwartet, dass der asiatisch-pazifische Raum im Prognosezeitraum mit der höchsten CAGR wachsen wird. Dies ist auf die zunehmende Verbreitung fortschrittlicher Technologien wie KI/ML und die zunehmende Einführung cloudbasierter Dienste in verschiedenen Branchen zum Aufbau einer sicheren Geschäftsinfrastruktur zurückzuführen. Steigende Investitionen ingenerative KIund der zunehmende Fokus von Unternehmen auf KI-Technologie dürften im Prognosezeitraum die Nachfrage nach Prozessen zur Generierung synthetischer Daten im asiatisch-pazifischen Raum ankurbeln.
Europa
Es wird erwartet, dass Europa im Prognosezeitraum aufgrund der Präsenz mehrerer Anbieter synthetischer Daten und des enormen Wachstums der Finanzierung für Anbieter strukturierter synthetischer Daten mit einer erheblichen jährlichen Wachstumsrate wachsen wird, um die Entwicklung der unternehmensinternen Fähigkeiten synthetischer Daten in Unternehmen voranzutreiben. Dieser Faktor dürfte das Marktwachstum im Prognosezeitraum vorantreiben.
Erfahren Sie, wie unser Bericht Ihr Geschäft optimieren kann, Sprechen Sie mit einem Analysten
Naher Osten, Afrika und Südamerika
Der Nahe Osten, Afrika und Südamerika wachsen aufgrund der Zunahmedigitale TransformationInitiativen in den Bereichen BFSI, Gesundheitswesen, Automobil sowie Medien und Unterhaltung. Die Integration künstlicher Intelligenz und maschineller Lerntechnologien mit der Finanz- und Automobilindustrie zur Generierung zuverlässiger synthetischer Daten treibt das Marktwachstum der Generierung synthetischer Daten in beiden Regionen voran.
WICHTIGSTE INDUSTRIE-AKTEURE
Wichtige Akteure konzentrieren sich auf die Generierung synthetischer Daten, um ihre Position zu stärken
Zu den Unternehmen zur Generierung synthetischer Daten gehören unter anderem Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc. und K2view Ltd. Steigende Investitionen in die Generierung synthetischer Daten für verschiedene Branchen helfen wichtigen Akteuren, ihren Wettbewerbsvorteil zu behaupten. Diese Unternehmen gehen auch strategische Partnerschaften, Übernahmen und Kooperationen ein, um ihr Geschäfts- und Vertriebsnetzwerk zu erweitern und das Marktwachstum aufrechtzuerhalten.
Liste der wichtigsten Unternehmen mit Profil im Markt für synthetische Datengenerierung:
- Datagen(UNS.)
- MEIST KI (Österreich)
- TonicAI, Inc. (USA)
- Synthese-KI (USA)
- GenRocket, Inc. (USA)
- Gretel Labs, Inc.(UNS.)
- K2view Ltd.(Israel)
- Hazy Limited.(VEREINIGTES KÖNIGREICH.)
- Replica Analytics Ltd. (Kanada)
- YData Labs Inc. (USA)
- Sogeti (Frankreich)
WICHTIGSTE ENTWICKLUNGEN IN DER BRANCHE:
- Juni 2023:Seeing Machine Limited arbeitete mit Devant AB, einem auf den Menschen ausgerichteten Anbieter synthetischer Daten, zusammen, um die Verkehrssicherheit durch das Verständnis des Verhaltens abgelenkter Fahrer zu verbessern. Diese Partnerschaft führte zur Integration der neuen Fahrzeugkabine von Seeing Machine mit der menschlichen 3D-Animation und computergenerierten Menschen von Devant, um die Entwicklung der Sensortechnologie in der Kabine voranzutreiben.
- Mai 2023:Synthesis AI hat einen neuen synthetischen Unternehmensdatensatz auf dem Snowflake-Marktplatz eingeführt, über den Kunden auf die sofort verfügbaren synthetischen menschlichen Gesichter von Synthesis AI zugreifen können, um visuelle Daten für das Computer-Vision-Modell zu entwickeln, ohne die Privatsphäre der Verbraucher von Synthesis AI zu gefährden.
- Dezember 2021:Gretel.ai hat sich mit Illumina, Inc. zusammengetan, um synthetische Daten für die Forschung in der Genomik und anderen verwandten Bereichen, einschließlich forensischer Biologie, Biotechnologie und biologischer Systematik, bereitzustellen und so die Entwicklung der Präzisionsmedizin voranzutreiben.
- Mai 2021:Parallel Domain, ein Anbieter einer Plattform zur Generierung synthetischer Daten, hat den branchenweit ersten öffentlichen Visualisierer für synthetische Daten auf den Markt gebracht, der den Brancheningenieuren hilft, direkt mit den vollständig gekennzeichneten synthetischen Kamera- und LiDAR-Datensätzen zu interagieren, um Lösungen für maschinelles Lernen zu testen, bereitzustellen und zu trainieren.
- April 2021:Unity Software Inc. hat synthetische Bilddatensätze eingeführt, um Modelle der künstlichen Intelligenz für Computer Vision zu entwickeln, die zu geringeren Kosten in der Architektur-, Ingenieur- und Baubranche (AEC) eingesetzt werden können.
BERICHTSBEREICH
Der Bericht bietet eine detaillierte Analyse des Marktes und konzentriert sich auf Schlüsselaspekte wie führende Unternehmen, Produkt-/Dienstleistungstypen und führende Anwendungen des Produkts. Darüber hinaus bietet der Bericht Einblicke in die Markttrends und beleuchtet wichtige Entwicklungen in der Branche der Generierung synthetischer Daten. Zusätzlich zu den oben genannten Faktoren umfasst der Bericht mehrere Faktoren, die zum Wachstum des Marktes in den letzten Jahren beigetragen haben.
Anfrage zur Anpassung um umfassende Marktkenntnisse zu erlangen.
Berichtsumfang und Segmentierung
|
ATTRIBUT |
DETAILS |
|
Studienzeit |
2021-2034 |
|
Basisjahr |
2025 |
|
Geschätztes Jahr |
2026 |
|
Prognosezeitraum |
2026-2034 |
|
Historische Periode |
2021-2024 |
|
Wachstumsrate |
CAGR von 31,1 % von 2026 bis 2034 |
|
Einheit |
Wert (in Mio. USD) |
|
Segmentierung |
Nach Datentyp, Anwendung, Branche und Region |
|
Nach Datentyp |
|
|
Auf Antrag |
|
|
Nach Branche |
|
|
Nach Region |
|
Häufig gestellte Fragen
Bis 2034 wird der Markt voraussichtlich 6905,32 Millionen US-Dollar erreichen.
Im Jahr 2025 wurde der Markt auf 603,61 Millionen US-Dollar geschätzt.
Der Markt wird im Prognosezeitraum voraussichtlich mit einer jährlichen Wachstumsrate von 31,1 % wachsen.
Es wird erwartet, dass das Testdatensegment marktführend sein wird.
Wachsende Nachfrage nach Datenschutz und Sicherheit, um das Marktwachstum voranzutreiben.
Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc., K2view Ltd., Sogeti und Hazy Limited sind die Top-Player auf dem Markt.
Nordamerika wird voraussichtlich den höchsten Marktanteil halten.
Es wird erwartet, dass das Gesundheitssegment im Prognosezeitraum mit einer bemerkenswerten jährlichen Wachstumsrate wachsen wird.
Nehmen Sie Kontakt mit unseren Experten auf Sprechen Sie mit einem Experte



- 2021-2034
- 2025
- 2021-2024
- 160
Erhalten Sie 30–60 Stunden kostenlose Anpassung
Regionale und länderspezifische Abdeckung erweitern, Segmentanalyse, Unternehmensprofile, Wettbewerbs-Benchmarking, und Endnutzer-Einblicke.
Verwandte Berichte
-
US +1 833 909 2966 (Gebührenfrei)
-
Nehmen Sie Kontakt mit uns auf